
01 编译与调试
编译与调试
程序调试
1.发生内存泄漏、程序等问题时,如何排查
- 日志
- 利用程序崩溃时的core dump文件进行分析
- 使用gdb运行core dump文件,并使用
bt命令打印函数调用栈
- 使用gdb运行core dump文件,并使用
- 使用valgrind等工具
2.程序崩溃的底层原理
- 应用程序不是自己挂了,而是OS检测到了它执行了非法操作,然会会给它发信号,如果该信号是“致命”的(进程没有捕获或无法处理),内核就会:
- 终止进程
- 可选地生成coredump
3.core dump是什么
- 当程序崩溃时,OS会将程序当时的内存镜像保存到一个文件中,通常名为
core或core.<pid>,它包含:- 程序崩溃时的寄存器状态
- 各线程的函数调用栈
- 内存中的全局变量 / 局部变量 / 堆内容
- 代码段映射、动态库加载信息
- 信号(如 SIGSEGV)
4.gdb的用法
- 参考另一篇笔记
5.gdb调试怎么调用函数
6.gdb怎么设置打印16位的变量?怎么跟踪变量,变量值改变时自动提示
7.gdb如何设置断点
8.为什么在那些IDE中以debug或者profile编译程序时,在运行崩溃时,会显示当前的函数调用栈及寄存器等信息
- 以debug或者profile编译程序时,编译器会加上
-g参数,使得程序附带了调试信息,能够把机器指令反映射成可读的代码 - IDE本质利用了GDB、LLDB、MSCV Debugger等调试器,这些调试器会捕获OS发给进程的异常信号比如
SIGSEGV,之后会读取CPU的寄存器,然后分析并展示那些相关信息,而不是像coredump文件那样保存到本地
9.函数调用栈是如何得到的(coredump中哪些东西是直接获得的,哪些是通过解析得到的)
- 通过gdb的
bt可以打印调用栈,其本质是通过直接读取寄存器和内存栈帧再结合调试符号表解析出来的 - 通过分析当前栈帧可以得到上个栈帧的地址
fp以及返回地址ra,之后再从符号表解析ra的具体内容,通过不断重复这个过程,就可以可视化整个调用栈
10.知道哪些调试方法
11.死机重启怎么调试
12.知道trace调试吗,知道怎么用吗
编译
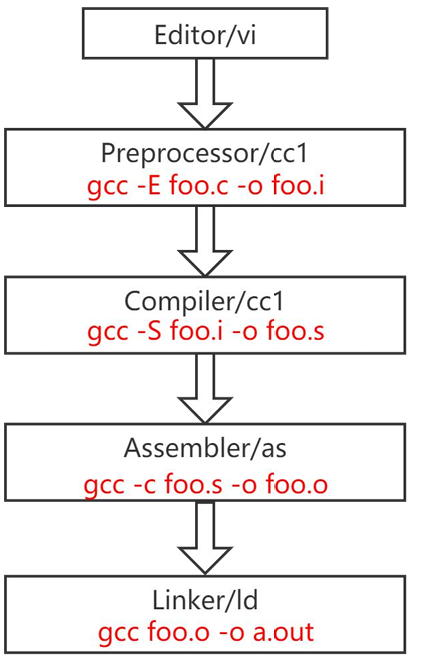
1.编译的流程是什么
将一个
.c程序编译成一个可执行文件通常包含4步:预处理:将各种宏定义翻译成C/C++语言
编译:将C/C++代码编译成汇编语言
汇编:对汇编代码进行处理,翻译成机器指令
链接:将用到的库文件和自己的机器指令汇总到一起(合并不同文件的同类内容,如
.text节区)
2.gcc有哪些参数

从上图可以知道,只要加了
-g其实就可以调试代码了,不一定非要使用debug模式编译才行
3.CMake或者各种IDE中的不同编译模式的区别
- gcc本身并没有什么debug、release等编译模式
- 本质上只是改变了gcc的编译参数,比如
-g、-O什么的
4.gcc的-g有什么用
- 作用:附带调式信息,gcc会在目标文件和最终可执行文件中加入一个调试数据段,它包含了:
| 调试内容 | 说明 |
|---|---|
| 源文件路径 | .cpp、.h 文件位置 |
| 行号信息 | 哪条机器指令对应哪一行源代码 |
| 函数名 / 类名 | 每个函数、类、成员变量的符号 |
| 局部变量 / 参数 | 它们的名字、类型、在栈中的偏移 |
| 宏定义信息 | 有时可用于宏回溯 |
| 源文件包含关系 | include 树信息 |
- 不加
-g只能看到地址,完全不可读
1 | Program received signal SIGFPE, Arithmetic exception. |
- 加
-g可以还原函数名、行号、变量
1 | Program received signal SIGFPE, Arithmetic exception. |
5.什么是链接
- 定义:在 C/C++ 程序中,链接是将编译生成的目标文件(
.o或.obj)合并成可执行文件的过程
6.动态/静态链接的区别是什么
区别主要在存储方式、加载时机、内存占用等方面
静态链接:
编译时完成链接:所有依赖的库代码直接嵌入到最终的可执行文件中
独立性强:程序运行时不需要外部库文件
体积较大:每个程序都包含一份完整的库代码副本
更新困难:库更新后,需要重新编译整个程序
动态链接:
运行时加载库:程序运行时才从外部加载共享库(
.so或.dll)共享性:多个程序可共享同一份库代码,节省内存
体积小:可执行文件仅包含对库的引用,不包含库代码本身
更新方便:替换库文件即可更新功能,无需重新编译程序
ELF文件
定义:ELF(Excutable Linkable Format)是一种Unix-Like系统上二进制文件的标准,符合ELF标准的ELF文件可以分为4类:

不是所有Linux下的二进制文件都是ELF文件,必须符合一定的格式才行!
ELF文件都遵循以下的格式:
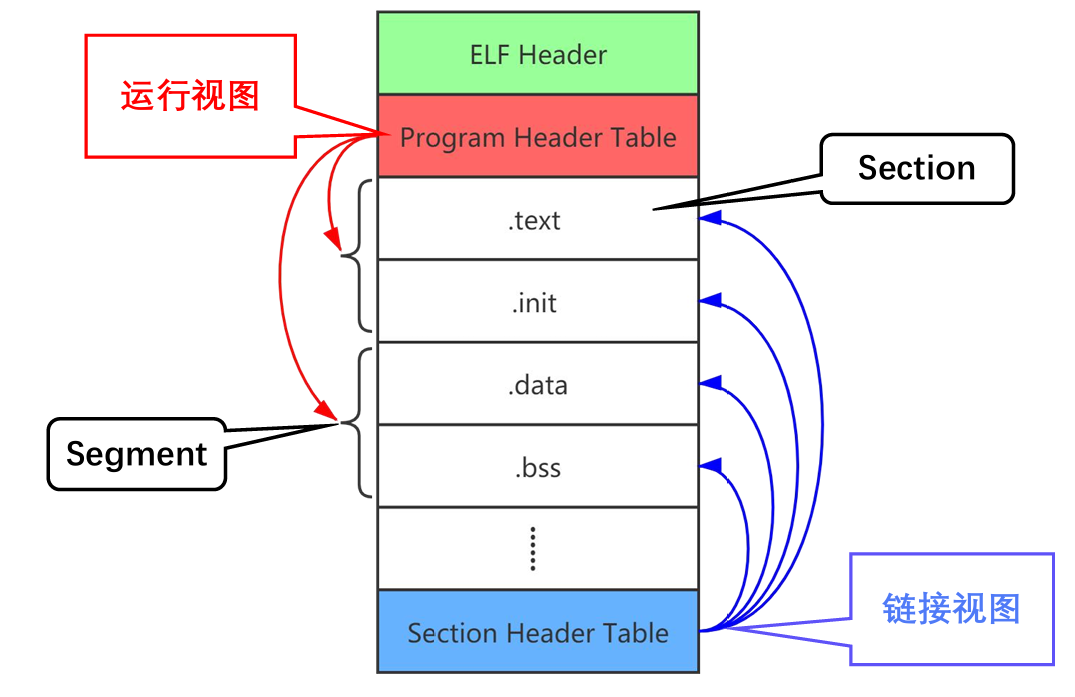
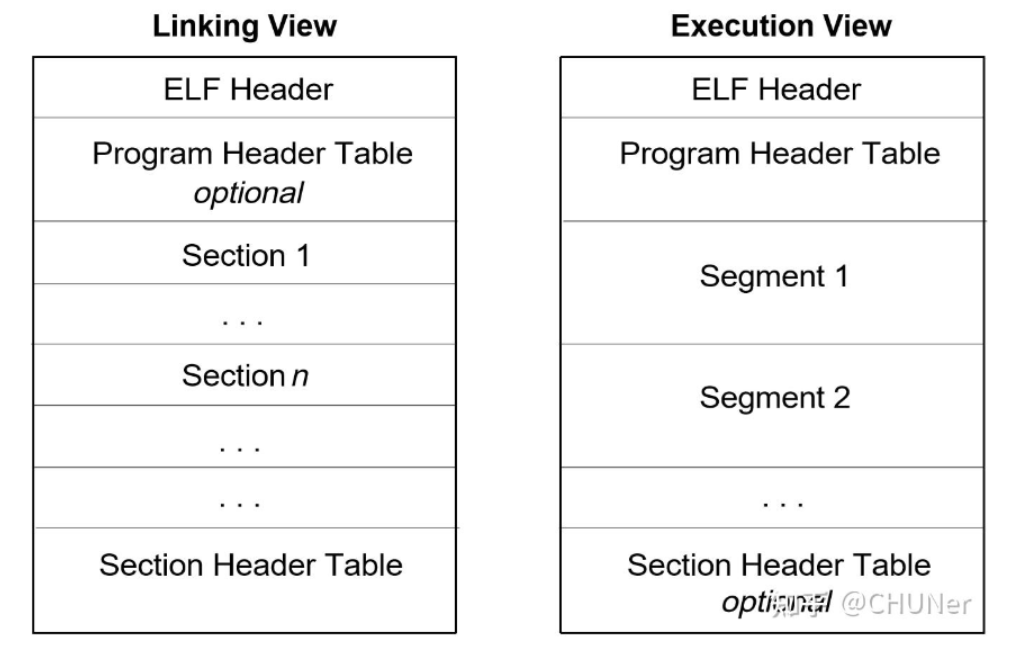
ELF 文件的作用有两个,一是用于程序链接(为了生成程序);二是用于程序执行。
针对这两种情况,可以从不同的视角来看待同一个目标文件。当它分别被用于链接和用于执行的时候,其特性必然是不一样的,我们所关注的内容也不一样。从链接和运行的角度,可以将 ELF 文件的组成部分划分为链接视图和运行视图这两种格式,重要组成部分如下:
- ELF Header:位于文件开始处,包含整个ELF文件的信息
- Section(节区):供链接器或调试工具使用,以静态视角描述一个文件的逻辑组成。在每个节中包含有指令数据、符号数据、重定位数据等等,例如.text、.data、.bss节…
- Section Header Table:描述文件中各段的信息(如代码段、数据段等),通常用于链接阶段
- Segment(段):供OS的加载器使用,以动态的视角描述一个文件如何加载到内存,包含多个节区
- Program Header Table:用于描述加载程序(如内核或动态链接器)如何将文件的各段加载到内存
对于可执行程序,Program Header是必须的,描述了不同的段即Segment,Section Header是可选的
对于链接程序,Program Header是可选的,Section Header是必须的,描述了不同的section
如何定义段和节区
- 法1.由链接脚本指定:
1 | SECTIONS { |
比如链接脚本代码就定义了一个段,里面包含了4个节区
- 法2.由gcc的一些指令在代码中定义新的节区
1 | int __attribute__((section(".profile"))) |
如果要精确控制新节区在内存中的位置,也要在链接脚本里写一下
ELF文件解析
虽然所有ELF文件都是按照这个格式排布的,但是不能直接通过查看一个二进制文件来分析(因为可读性太差),通常需要使用一些工具(比如binutils)来分析ELF文件

下面举一些例子来说明如何查看一个ELF文件:
- ELF Header:
readelf -h - Program Header Table:
readelf -l - Section Header Table:
readelf -S - 符号表:
readelf -s
符号表
1.符号表的定义
- 符号表是ELF文件中的一个节区(.symtab 或 .dynsym),存储了程序中所有符号(包括定义的、引用的、导出的)的名称、类型、地址等信息(但是==不能==知道符号是在哪个文件定义的)
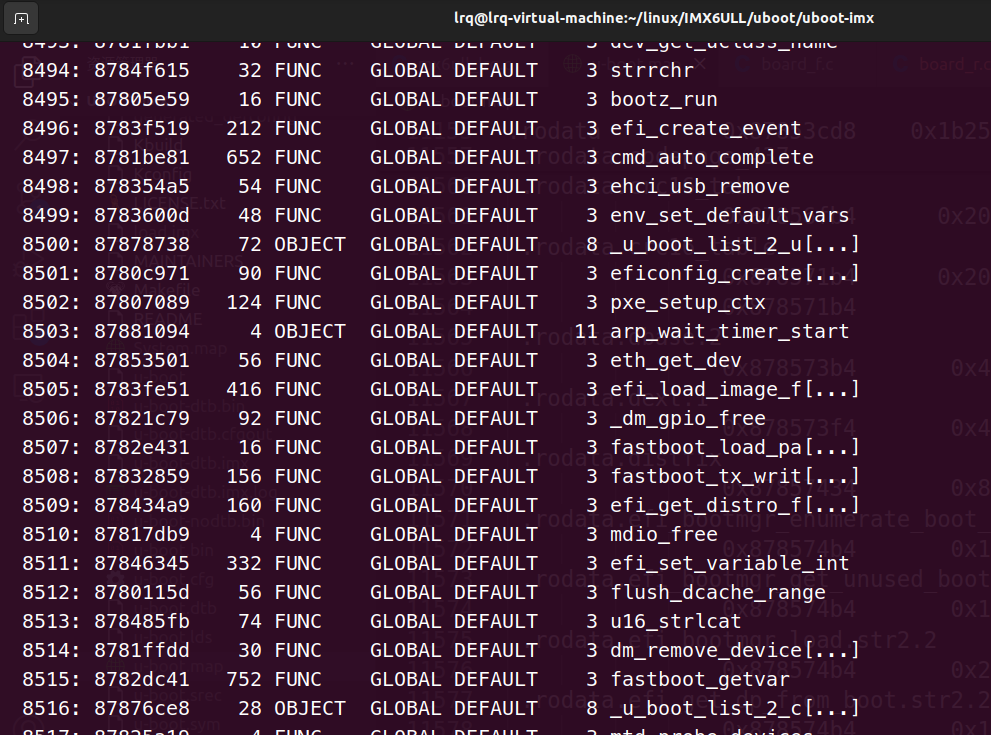
符号可以是:
- 函数名(如
main、printf) - 全局变量(如
int global_var;) - 静态变量(如
static int local_var;)
2.符号表的作用
- 链接阶段:帮助链接器找到符号的定义和引用关系
- 调试阶段:提供符号名到地址的映射(如
gdb调试时显示函数名) - 动态链接:支持运行时符号解析(如共享库中的函数)
3.符号表的引用:指的是使用代码中未定义的符号。编译阶段,如果遇到未定义的符号,会标成UDN,在链接的时候被绑定
4.符号导出:将符号标记为可被其他模块访问的过程。例如:
- 在库中导出函数供外部调用
- 在内核模块中导出符号供其他模块使用
实现方式
- C 语言:使用
extern或__attribute__((visibility("default"))) - Linux 内核:通过
EXPORT_SYMBOL()宏导出符号
| 概念 | 描述 | 示例 |
|---|---|---|
| 符号表 | 存储符号名称、类型和地址的 ELF 节区 | .symtab, .dynsym |
| 符号引用 | 代码中使用的未定义符号,需链接器解析 | extern int x; |
| 符号解析 | 将引用绑定到定义的链接过程 | 将 printf 绑定到 libc.so |
| 符号导出 | 显式标记符号为外部可见 | EXPORT_SYMBOL() |
5.为什么Linux内核模块中大部分函数要加static关键字?
- 早期Linux中,如果全局变量或函数不加static,会被注册到Linux运行时维护的全局的符号表中,那么很可能发生命名冲突之类的
- 现代Linux中,全局变量或函数即使不加static,默认也不会被注册到Linux运行时维护的全局的符号表中,只有显式导出时才会。所以一般的函数、变量不加
static也行
6.如何看内核的符号表
- 使用
readelf或nm分析vminux文件:它是未压缩的内核的ELF文件。包含所有符号(包括未加static的函数和变量),无论是否导出 - 查看内核运行时动态的符号表:该符号表不包含没被导出的符号
1 | cat /proc/kallsyms | grep "函数名" # 按符号名查找 |
map文件
1.定义:
.map文件(链接映射文件)是链接器在生成可执行文件或库时生成的一个文本格式的报告文件,它详细描述了:
- 内存布局(Memory Layout):程序中的各个段(Section)如何被映射到内存地址
- 符号地址(Symbol Addresses):全局变量、函数等符号的最终内存地址
- 库依赖(Library Dependencies):链接了哪些库,以及它们的符号如何被解析
- 大小信息(Size Information):代码段、数据段的大小,以及各个符号占用的空间
2.典型的map文件解析:
1 | Memory Map |
3..map文件和ELF文件中的符号表的区别
| 特性 | .map文件 |
ELF 的 .symtab |
|---|---|---|
| 格式 | 文本文件 | 二进制数据(需 readelf或 nm解析) |
| 内容 | 内存布局、符号地址、库依赖 | 仅符号表(无内存布局) |
| 用途 | 调试、优化、内存分析 | 链接、动态加载、调试 |
| 生成方式 | 链接器显式生成(-Map) |
默认包含在 ELF 文件中 |
遇到的问题:
1.如果一个函数在源码中通过条件编译之类的操作定义了多次,如何知道最终被使用的到底是哪个?
- 看
.map文件或者


