
XV6
XV6
1.调试
1.首先在一个终端里通过make qemu-gdb启动gdbserver
2.配置vscode的lauch.json,包括gdb路径、输入参数之类的
3.使用vscode开始调试
2.RISC-V ISA
ISA应该包含以下内容:
- 指令集
- 寄存器集
- 内存模型
- 异常与中断处理机制
- 特权级别
- …(不同ISA包含的东西不一样)
参考链接
- ch02-riscv-isa-introduction.pdf
- ch05-assemble-programming.pdf
- ch10-trap-exception.pdf
- RISC-V-中文参考手册
- RISC-V ISA手册Part2 : 特权级别相关
- 特权级机制 - uCore-Tutorial-Guide-2024S 文档
特权等级
RISCV包含4个特权等级
| 级别 | 编码 | 名称 |
|---|---|---|
| 0 | 00 | 用户/应用模式 (U, User/Application) |
| 1 | 01 | 监督模式 (S, Supervisor) |
| 2 | 10 | H, Hypervisor |
| 3 | 11 | 机器模式 (M, Machine) |
RISC-V 架构中,只有 M 模式是必须实现的,剩下的特权级则可以根据跑在 CPU 上应用的实际需求进行调整:
- 简单的嵌入式应用只需要实现 M 模式
- 带有一定保护能力的嵌入式系统(RTOS)需要实现 M/U 模式
- 复杂的多任务系统(如Linux)则需要实现 M/S/U 模式
- 到目前为止,(Hypervisor, H)模式的特权规范还没完全制定好
不同特权等级的区别是什么?
- 高特权等级相对于U-mode,只是多了一些指令和寄存器、能访问更多的PTE,除此之外没啥区别
- 只有S-Mode能控制MMU的页表基址(
satp)
常见指令
RISC-V的基础整数指令集(I)主要包含以下几类指令:
- 整数寄存器操作:算数运算、逻辑运算
- 控制流指令:无条件跳转、条件分支
- 内存访问指令:寄存器存储到内存(
sd)、内存加载到寄存器(ld) - 内存屏障指令:
fence等 - 系统调用/断点:
ecall、ebreak - CSR操作指令:对CSR寄存器进行读写
- 伪指令:空操作、
mv….
RV32I/RV64I 不包含以下功能(需通过扩展模块实现):
- 乘除法:需
M扩展(指令如MUL、DIV) - 原子操作:需
A扩展(如LR/SC、AMO) - 浮点运算:需
F(单精度)/D(双精度)扩展 - 压缩指令:需
C扩展(16 位指令编码)
特权指令
ecall:
(1)将CPU从用户模式切换到SVC模式
(2)保存当前的PC到SEPC寄存器
(3)将PC指针跳转到STVEC寄存器指向的指令
RISC-V的
ecall的设计原则是使其尽可能的简单,所以不会切换页表,也不会保存上下文,这些都要靠软件实现
sret:
(1)特权等级切换:将CPU从SVC模式切换到用户模式
(2)从sepc恢复pc的值
(2)重新开启中断
寄存器
基础整数寄存器
- RISC-V 基础指令集(RV32I/RV64I)包含32个通用寄存器和一个PC指针,每个寄存器的大小和处理器的位宽相关,可能为32/64/128位
- 每个寄存器在编程时有特定的用途和别名,由ABI决定
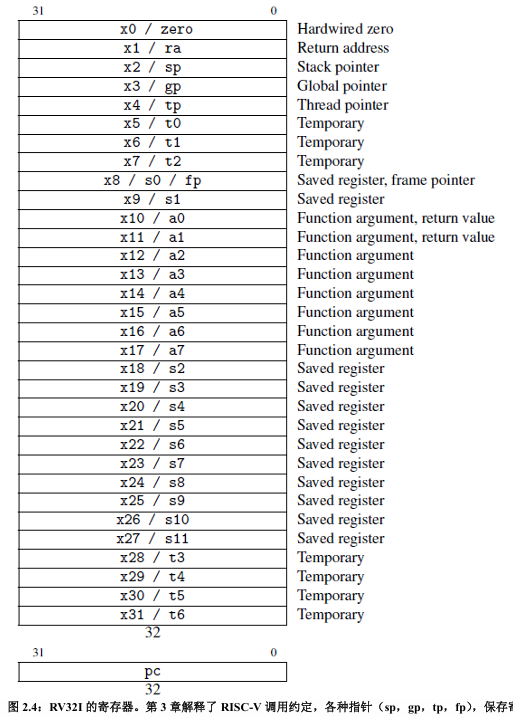
| 寄存器 | ABI 名称 | 用途 | 是否调用保存 |
|---|---|---|---|
x0 |
zero |
硬编码为 0,写入无效,读取始终返回 0 | - |
x1 |
ra |
返回地址(Return Address),用于函数返回(如 ret 指令) |
否 |
x2 |
sp |
栈指针(Stack Pointer),指向当前栈顶 | 是 |
x3 |
gp |
全局指针(Global Pointer),用于访问全局数据(可选优化) | - |
x4 |
tp |
线程指针(Thread Pointer),用于线程局部存储(TLS) | - |
x5-x7 |
t0-t2 |
临时寄存器,用于短期存储,函数调用后可能被覆盖 | 否 |
x8 |
s0/fp |
帧指针(Frame Pointer),用于调试或栈帧定位(可选) | 是 |
x9 |
s1 |
保存寄存器,函数调用后需恢复 | 是 |
x10-x11 |
a0-a1 |
函数参数/返回值,传递前两个参数或返回值 | 否 |
x12-x17 |
a2-a7 |
函数参数,传递第 3~8 个参数 | 否 |
x18-x27 |
s2-s11 |
保存寄存器,函数调用后需恢复 | 是 |
x28-x31 |
t3-t6 |
临时寄存器,函数调用后可能被覆盖 | 否 |
- “是否调用保存”指的是,发送函数调用时,是否会保存该寄存器的值,还是直接覆盖
浮点寄存器
如果实现 F 或 D 扩展(单精度/双精度浮点),RISC-V 提供 32 个浮点寄存器 f0-f31,位宽由扩展决定:
F扩展:32 位(单精度)D扩展:64 位(双精度)
状态控制寄存器
不同的特权级别分别对应各自的一套状态控制寄存器CSRs,用于配置和监控 CPU 状态(==具体有哪些==,请看RISC-V ISA手册Part2的Table 2.2)
高级别的特权级别下可以访问低级别的CSR, 譬如 Machine Level 下可以访问 Supervisor/User Level 的 CSR,以此类推, 但反之不可以
RISC-V 定义了专门用于操作 CSR 的指令
RISC-V 定义了特定的指令可以用于在不同特权级别之间进行切换
3.RISC-V ABI
ABI(Application Binary Interface,应用程序二进制接口)是软件组件之间的底层交互规范,定义了程序如何编译、链接、执行,以及不同模块(如应用程序、库、操作系统)之间的二进制兼容性规则。之所以叫做二进制接口,是因为它和在同一种编程语言内部调用接口不同,是汇编指令级的一种接口。它介于硬件(ISA)和高级语言(如C/C++)之间,直接影响程序的运行行为。
- ABI是S-Mode为U-Mode提供的接口,而SBI是M-Mode为S-Mode提供的接口
核心内容:
- 函数调用约定(Calling Convention):参数如何通过寄存器/栈传递(如 RISC-V 用
a0-a7) - 系统调用约定:系统调用号存放位置(如 RISC-V 用
a7) - 数据对齐和结构体布局
- 寄存器保存规则(哪些寄存器由调用者/被调用者保存)
函数调用约定
这部分内容如上面的寄存器表格定义,值得注意的是,由于ABI是汇编级别的约定,所以我们普通程序员基本上是不用太关注的,比如函数使用哪个寄存器传参,编译的时候编译器就已经帮我们生成了这部分(把参数存到a_x寄存器里)的汇编代码了
参数传递规则:
整数参数:通过
a0-a7传递(前 8 个),超出部分通过栈传递浮点参数:通过
fa0-fa7传递(前 8 个),超出部分通过栈传递混合参数:整数和浮点参数分开传递
返回值:
整数返回值:存放在
a0(和a1,如果 64 位值)浮点返回值:存放在
fa0(和fa1,如果双精度)
栈帧管理:
栈对齐:栈指针
sp必须保持 16 字节对齐保存寄存器:被调用者(Callee)需保存
s0-s11和fs0-fs11
函数调用流程
RISCV的寄存器可分为以下2类:
- Caller-saved:调用者负责保存(如
a0-a7) - Callee-saved:被调函数负责保存(如
s0-s11、fp、ra)
1.调用者funA准备参数,RISC-V 通过寄存器 a0-a7传递前 8 个参数,多余参数通过栈传递
2.调用者funA通过jal执行函数跳转,并自动将返回地址存入ra
3.被调函数funB首先移动sp来创建栈帧(会给局部变量预留空间),接着保存funA的ra和fp到栈帧中作为初始化
4.更新当前(被调函数)的fp寄存器
5.执行函数内的具体逻辑
6.将funB的返回值保存到a0寄存器
7.从栈帧中恢复ra和fp寄存器的值
8.使用ret指令进行返回
局部变量保存在哪
- 如果局部变量较少的话,保存在局部寄存器中;如果局部变量多的话,保存在栈帧中
上下文保存
ra(return address):函数调用会发生指令跳转,该寄存器保存了跳转前的PC寄存器的值,以便函数执行完时跳转回去继续执行fp(frame pointer):存储当前栈帧的地址sp(stack pointer):存储当前栈底部的地址
栈(Stack):用户进程内存空间的一个重要分区,通常自顶向下生长,由
sp指针指向当前栈底的位置。每个线程都有独立的、固定大小的栈,所以一个用户进程会有多个栈区栈帧(Stack Frame):是计算机程序在执行过程中,==调用栈的独立单元==,用于存储单个函数调用相关信息的一块内存区域。每当一个函数被调用时,一个新的栈帧会被压入调用栈;当函数返回时,对应的栈帧会被弹出,其实就是函数调用时被保存的上下文
- 用于存储函数跳转前的各个寄存器的值:函数的传入参数(a0~a7),函数的返回地址(ra),上一个栈帧的地址(fp)
假如在
funA()中调用funB(),funB()创建的栈帧保存的是执行funA()时的ra、fp、a0之类的寄存器的值- 由
fp寄存器存储当前栈帧的起始地址
从汇编的角度看函数调用:
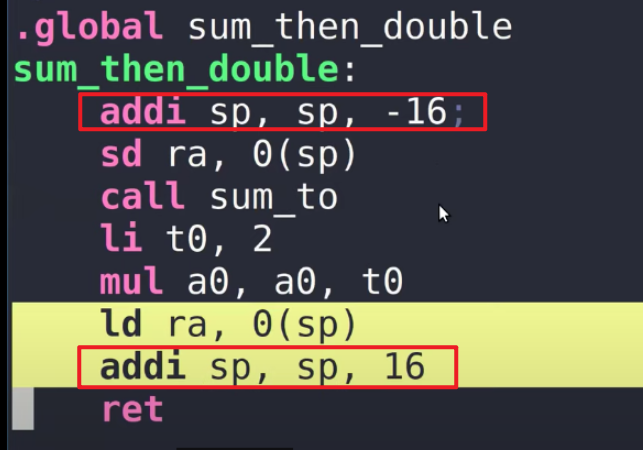
- Stack Frame必须要被汇编代码创建,所以是编译器生成了汇编代码,进而创建了Stack Frame。对
sp的减小和增大,其实就是Stack Frame的压栈(创建)和出栈(删除)
为什么每次调用函数时,栈就要立即分配16字节
- 因为栈帧的最小大小为16字节(上一个函数调用的栈帧地址 + 上一个函数调用返回地址)
- 不同函数调用时,分配的栈帧大小是不同的,这和需要保存的局部变量和寄存器相关,但至少得包含存储
ra和上个fp寄存器的大小(上面的代码中,栈帧大小为16字节)
什么需要栈帧寄存器
fp
fp用来存储当前栈帧的起始地址,这个地址用于在函数内定位参数和局部变量:参数通过fp + offset访问,局部变量通过fp - offset访问
某线程的栈区的示意图:由3个栈帧组成

系统调用约定
- 系统调用号:存放在
a7 - 参数:通过
a0-a5传递(==最多 6 个==) - 返回值:成功时返回
a0,错误时返回-errno(类似 Linux)
数据布局与对齐
基本类型大小:
| 类型 | RV32 | RV64 |
|---|---|---|
int |
4 字节 | 4 字节 |
long |
4 字节 | 8 字节 |
| 指针 | 4 字节 | 8字节 |
double |
8 字节 | 8 字节 |
float |
4 字节 | 4 字节 |
结构体对齐:
- 默认对齐规则:字段按自身大小对齐(如
int对齐到 4 字节)
参考链接
4.Trap
定义
用于将程序从用户态切换到内核态的事件,它是操作系统实现特权隔离和安全控制的核心机制之一
触发场景
Trap 通常由以下3类事件触发:
1.系统调用(Syscall)
- 用户程序主动请求内核服务(如读写文件、创建进程等),通过
ecall(RISC-V)或syscall(x86-64)指令触发 - 例如:Linux 中调用
write()会触发 Trap,进入内核的sys_write处理函数
2.异常(Exception)
- 由程序执行错误(如除零、非法内存访问)或调试需求(如断点)触发
- 例如:访问
NULL指针会触发 缺页异常(Page Fault)或 段错误(Segmentation Fault)
RISC-V包含的异常如下(scause寄存器的值):
| 异常代码 | 助记符 | 描述 |
|---|---|---|
| 0 | 0 | 指令地址未对齐 (Instruction address misaligned) |
| 0 | 1 | 指令访问错误 (Instruction access fault) |
| 0 | 2 | 非法指令 (Illegal instruction) |
| 0 | 3 | 断点 (Breakpoint) |
| 0 | 4 | 加载地址未对齐 (Load address misaligned) |
| 0 | 5 | 加载访问错误 (Load access fault) |
| 0 | 6 | 存储/原子操作地址未对齐 (Store/AMO address misaligned) |
| 0 | 7 | 存储/原子操作访问错误 (Store/AMO access fault) |
| 0 | 8 | 用户模式系统调用 (Environment call from U-mode) |
| 0 | 9 | 监管模式系统调用 (Environment call from S-mode) |
| 0 | 11 | 机器模式系统调用 (Environment call from M-mode) |
| 0 | 12 | 指令页错误 (Instruction page fault) |
| 0 | 13 | 加载页错误 (Load page fault) |
| 0 | 15 | 存储/原子操作页错误 (Store/AMO page fault) |
3.中断(Interrupt)
- 由外部设备(如键盘、定时器)异步触发
系统调用和异常的触发是同步的,而中断是异步的
相关寄存器
- MODE:当前CPU的特权模式
- SATP:当前MMU所使用页表的基址
- STVEC:内核中处理Trap的指令的地址
- SEPC:备份发生Trap时PC指针的值,结束时返回
- SSCRATCH:临时存储数据,通常用于上下文保存时,切换用户/内核栈,相当于一个cache
- SCAUSE:保存了trap是什么类型(中断/系统调用/异常)
- SSTATUS:中断使能控制;trap发生时的特权级保存;sret返回时的特权级设置
- 32个通用寄存器:作为上下文被保存
需要注意的是这些寄存器是S态的CSR寄存器。M态还有一套自己的CSR寄存器mcause,mtvec…
Trap的处理流程
Trap的处理流程由OS决定,不同OS一般不同,下面以XV6的系统调用为例:
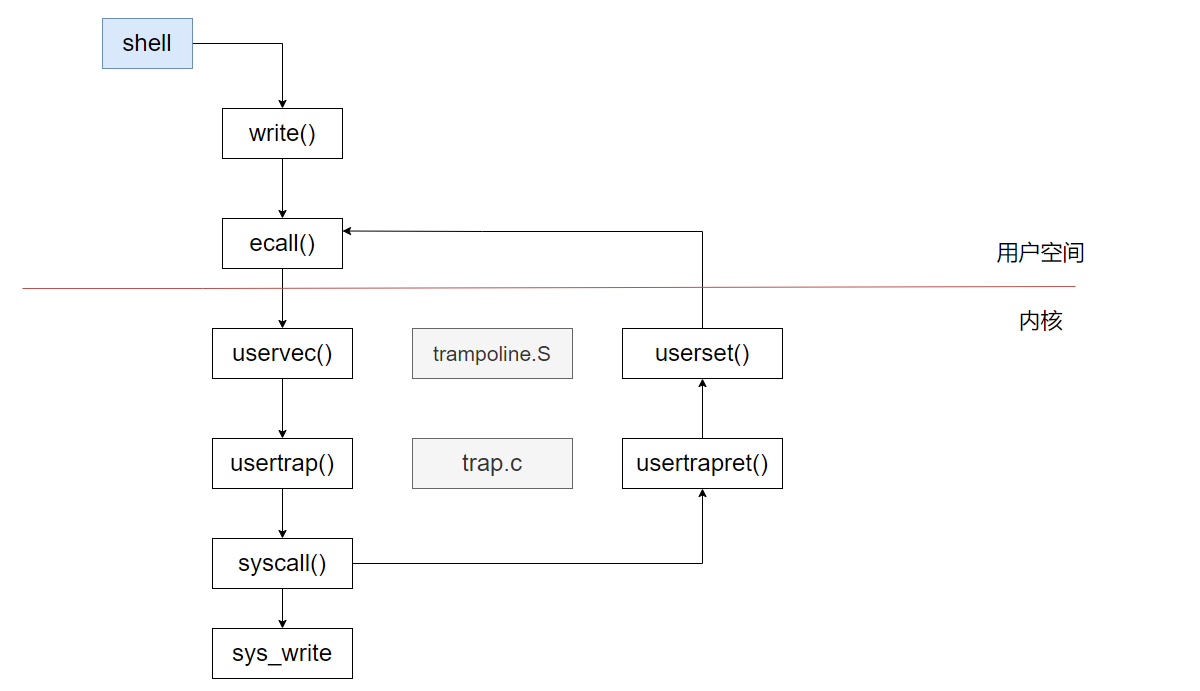
从用户态U跳转到内核态S
- 用户态程序将
a7存放系统调用号,a0 - a5存放系统调用的参数,并调用ecall指令触发特权等级的切换,调用完毕后会将系统调用的返回值放在a0寄存器中 - cpu会自动修改
sepc寄存器的值为执行ecall后的下一条指令的地址,用于当系统调用完毕后从内核态返回跳转到此地址继续执行代码 scause寄存器会被cpu修改成产生此次trap的原因,比如scause为8时代表为U模式下的系统调用- 在系统刚启动、从内核空间进入到用户空间之前,内核会设置好STVEC寄存器指向内核希望
trap代码运行的位置,这样通过ecall陷入到内核态时就会去stvec中保存的地址开始执行代码
内核态处理流程
- 当
ecall进入内核态后,内核需要保存用户态的寄存器以便在结束系统调用后恢复用户态的执行逻辑,但是XV6的用户空间和内核的page table不同,在切换页表前,无法访问内核的地址空间,故无法在内核中备份寄存器的值。所以XV6引入了一个特殊的设计:内核在创建一个进程时会动态分配一个物理页(trap frame page),其PTE的权限设置为只能在S-mode下访问,并将其映射到用户页表中。这样就可实现在发生trap并还没切换页表时,实现用户寄存器的备份 - 进入内核态后
sscratch寄存器中保存了用户页表的trapframe的虚拟地址,将其与a0寄存器交换,接着依次保存x0-x31的所有寄存器以及S态的sstatus和sepc寄存器保存到该内存页中 - 将用户态的寄存器保存后,内核从
trapframe读取内核页表的基址,实现页表的切换,并将sp指向内核栈 - 之后执行
trap的具体处理流程syscall(),根据p->trapframe访问内核中备份的用户进程的各寄存器的值。首先判断取出a7寄存器中的系统调用号进行分发,然后再将a0-a5系统调用的参数取出随之去进行处理,并将结果存到p->trapframe->a0
从内核态S跳转到用户态U
- 首先从
trapframe中恢复x0-x31寄存器,将sp指向用户栈,然后将sscratch中的值设置为用户页表中trapframe的地址 - 在返回到用户态之前需要设置
sstatus的SPP位为0告诉cpu将特权等级设置为U模式 - 将用户页表的基址写入
satp,切换页表并清空页表缓存 - 调用
sret返回到用户态,pc返回到之前sepc寄存器中保存的地址
新增系统调用的流程
- (1)在==用户空间==创建一个与系统调用同名的存根函数,这个函数通过汇编实现,在被调用的时候,会将系统调用号放到a7寄存器中,并调用
ecall指令触发一个trap - (2)在内核空间中有个数组存了所有系统调用的编号,在此数组中新增新的编号,对应用户新添加的系统调用
- (3)kernel中实现
sys_xxx,作为系统调用的真正实现
内核会在
trap的处理中,调用syscall()并通过a7寄存器里存的编号来调用真正的系统调用
为什么每个用户进程的页表中都要映射trampoline和trapframe
RISC-V在执行ecall指令时并不会切换页表,而是让CPU进入SVC模式,并触发一个trap,程序将自动跳转到STVEC寄存器所指的地址的指令。此时的页表还是用户进程的页表,而后会切换到内核页表。但是在切换页表的过程中,pc始终在uservec()函数内,为了让程序能在切换了地址空间后继续正常地执行该函数,需要在2个页表中都建立对该函数所在物理页(traponline)的映射
- 注意,虽然用户进程的页表有这2个内核页表项的映射,但是在CPU处于User Mode的时候并不能访问,因为他们的
PTE_U标志位没有置位,这保证了trap的安全性 - 只有在trampoline的代码段能实现页表的切换,因为内核和用户进程的页表,只在trampoline处有相同的PTE(虚拟地址、物理地址都一样),即切换页表后能继续执行后边的指令
Trap时如何保存上下文
在每个用户进程的页表中,都保存了一个trap frame page,其地址被存在SSCRATCH寄存器里。该页表项可以用来保存和恢复用户态CPU的通用寄存器的值;并且该页表项也保存了内核页表的地址,以便后续切换页表
为什么需要保存上下文?
- 因为在进入内核态后,内核将覆盖所有CPU寄存器的值,如果我们想在处理完trap后正确地恢复用户进程,则需要备份当前的寄存器的值
为什么不在栈中保存上下文?
- 1.防止用户程序恶意修改栈的数据,而导致内核恢复上下文的时候读取到被篡改的数据
- 2.简化上下文切换的流程
系统调用如何传递参数
向内核传递的参数会自动被放到a0~`a5通用寄存器中,并在由用户态切换到内核态时,被保存在p->trapframe`中。在内核中通过读取这几个寄存器的值来得到系统调用的传递的参数
XV6处理异常的方法
- 异常发生在用户进程:直接kill了该进程
- 异常发生在内核:发生kernel panic
真实操作系统远比这复杂
参考链接
- Lec06 Isolation & system call entry/exit (Robert) | MIT6.S081
- 实现应用程序以及user文件夹 - uCore-Tutorial-Guide-2024S 文档
5.中断管理
如何对硬件设备编程
每个硬件设备都有个固定的物理地址(这又设备厂商决定)通过对这些物理地址执行CPU的load、store指令,即读写设备的控制寄存器,即可完成对设备的编程
由于OS无法直接访问物理地址,所以在对硬件编程时,通常要和操作内存一样,需要创建个PTE来获得一个与设备物理地址对应的虚拟地址,后续通过该虚拟地址来对寄存器进行读写
中断相关的寄存器
- SIE(Supervisor Interrupt Enable):有一个bit用于开启/关闭某个中断(外部设备、定时器、软件等)
- SSTATUS(Supervisor Status):有一个bit用于开启/关闭所有中断
- SIP(Supervisor Interrupt Pending):用于查看发生的是什么中断
- SCAUSE:表明当前进入trap的原因
- STVEC:内核中处理Trap的指令的地址
- SEPC:保存被打断的指令以便结束trap后继续执行
中断的路由
- 当一个中断产生,它是如何被送到某个CPU中的,这被称为中断的路由
- 在RISC-V中这个过程由PLIC(platform level interrupt controller)平台中断控制器来控制,即PLIC掌管了中断的接收和分发
中断太频繁怎么办
如果使用了高速设备,那么设备产生中断的频率可能非常高。比如千兆网卡可能1us就会接收到一个数据进而产生一个中断,如果还像低速设备那样每接收到一次数据就发生一个trap然后CPU去读外设寄存器来将数据存到内存里,那么效率就太低了,对于此问题有以下解决办法:
- 1.关闭中断,使用轮训的方式去读寄存器,这样一次可能可以读多条数据,也可能没有数据而浪费CPU的时间
- 2.使用DMA(直接内存映射),DMA可以把外设寄存器的值直接映射到内存中,省去了CPU先发生trap,然后执行load指令读取外设寄存器的时间
6.内存管理
相关硬件
- MMU
- 仅在U-Mode和S-Mode使用,M-Mode下直接访问物理内存
- MMU不保存页表,它只会保存根页表的物理地址(类似指针)
- satp寄存器:控制MMU的开启/关闭、根页表的地址、分页模式。其字段组成如下:| MODE (4 bits) | ASID (16 bits) | PPN (44 bits) |
- MODE:分页模式(如
8表示 Sv39) - ASID:地址空间标识符(可选,用于 TLB 隔离)
- PPN:根页表的物理地址,实际不是完整的物理地址,只是物理页号,page directory的offset都为0所以省略了。
- MODE:分页模式(如
- TLB
- 修改
satp之后,必须通过sfence.vma清空TLB的缓存
- 修改
- 物理内存
- CPU访问物理内存是以字节为单位访问的,但是OS以及MMU却以页为单位对物理内存进行管理/翻译
| 场景 | 访问/管理单位 | 示例 |
|---|---|---|
| CPU 指令访问内存 | 字节 | lw a0, 4(sp) 读取 sp+4 地址的 4 字节数据 |
| OS分配内存 | 页(如 4KB) | xv6 的 kalloc() 返回一个 4096 字节的物理页 |
| MMU 地址转换 | 页 | 虚拟地址 0x1000-0x1FFF → 物理页帧 0x5000(通过 PTE 映射) |
内存布局
RISC-V地址空间
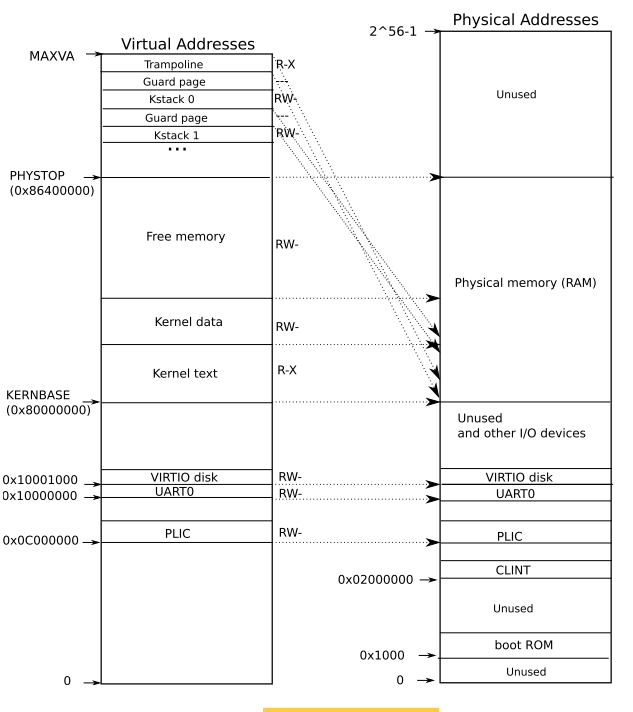
如右图所示,在整个RISCV的地址空间中,物理内存从0x80000000开始,所以内核加载到此地址
内核空间内存布局
XV6内核的内存布局如左图所示,它和物理内存是直接映射的。XV6和Linux的内核布局有很大的区别,XV6中内核维护了一个单独的页表,独立于用户进程。而Linux中每个进程地址空间的高位包含了对于内核代码和数据的映射,即用户页表直接包含了对内核的映射,不过用户态下无权访问
用户进程内存布局
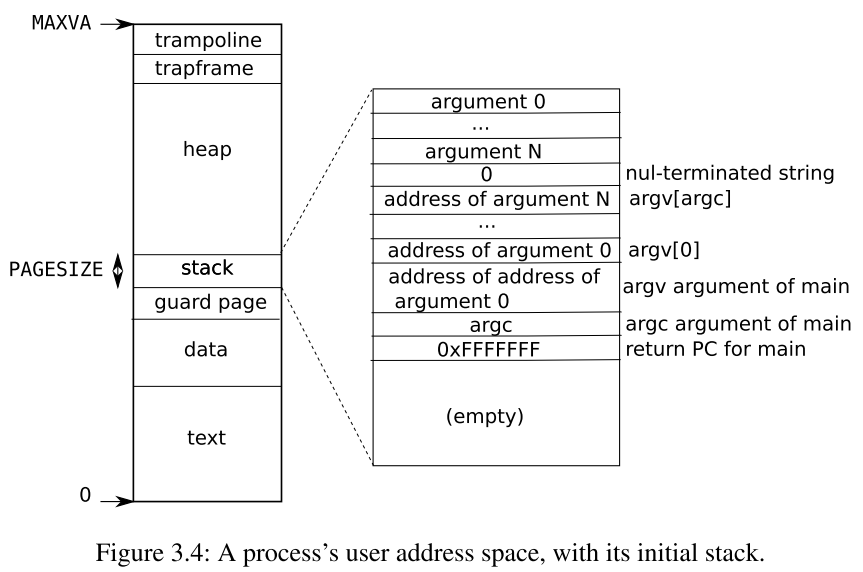
用户进程和内核的内存布局(页表)的区别
(1)映射内容:
- 内核页表:映射整个内核地址空间,包括内核代码段、内核数据段、硬件外设的寄存器以及内核栈等
- 用户进程页表:包括用户程序的代码段、数据段、堆和栈
(2)地址范围:
- 内核页表:从0x0000开始,但是低地址部分是硬件外设寄存器的映射,内核代码是从0x80000000开始的
- 用户进程页表:也从0x0000开始,低地址部分直接就是用户程序的代码段
debug时通过当前指令的地址,就能判断是在内核还是用户进程中了
(3)生命周期和管理方式:
- 内核页表:在系统启动时被创建,一直存在,且相对静态,只会微调,比如加载新的内核模块
- 用户进程页表:在用户进程创建时被创建,结束时被销毁,且会随着内存分配动态变化,内核会根据进程的内存申请(如
malloc操作)和释放(如free操作)来动态地更新页表
页表与地址转换
页表的定义:OS所维护的一种数据结构,保存了虚拟内存地址到物理内存地址的映射。基于页表,MMU才能正常的工作
- 不同OS对于页表的管理也有很大的区别:
- 比如XV6对内核维护了个单独的全局页表,实现对内核地址空间的映射;对每个进程各自维护了一个页表,实现对该进程用户空间进行映射
- Linux每个进程的页表同时包含了用户空间和内核空间的映射
页表是以==内存页==为粒度进行映射的,就如它的名字一样,并不是以字节为单位映射
引入页表的作用:
(1)实现虚拟内存:物理内存资源是有限的。虚拟内存技术允许程序使用比实际物理内存更大的地址空间。通过页表,操作系统可以将虚拟地址空间映射到物理内存空间。比如一个32位机器的物理内存只有1G,但通过虚拟内存,其内存的地址空间可达到4G,页表可以将虚拟地址空间中的页面映射到物理内存中的页面或者磁盘上的交换空间(当物理内存不足时),使得程序能够正常运行,就好像拥有足够的物理内存一样
(2)实现内存的隔离:通过给每个进程实现一个独立的页表,不同进程之间就无法直接访问对方的内存空间,从而防止一个进程意外访问或修改另一个进程的内存数据
(3)实现访问控制:页表项除了保存了虚拟地址到物理地址的转换关系,还保存了此页表项的访问权限,比如有的页表项就只能在内核中访问,用户空间无法访问。可以防止用户修改内核的内存,或者修改未被分配的内存空间,提供了一种保护机制
RISC-V的分页机制
RISC-V ISA支持多种分页机制,通过satp寄存器控制,XV6使用的是Sv39分页机制,除此之外还有Sv32、Sv48等分页机制
为什么要引入多级页表?
多级页表是现代操作系统管理虚拟内存的核心机制,其设计目的是为了解决单级页表空间浪费严重的问题,同时兼顾查找效率和灵活性。下面分析单级页表的内存占用:
- Sv39 的虚拟地址空间大小:2^39=512GiB
- 页大小:4KiB
- 页表项大小:8 B
那么:
- 虚拟页数 = 2^39/2^12 = 2^27=134,217,728 个页
- 单级页表大小 = 2^27 * 8B=1GB
对于每个进程,即使该进程只用了很小的内存,OS都需要维护这么大一个页表,非常浪费空间!
所以OS引入了多级页表,对于多级页表,OS只会固定分配L2 Page Directory的内存(512*8=4KB),L1和L0的Page Directory都是动态分配的,所以最小只需要3 * 4=12KB的内存来存储页表
虚拟地址结构
Sv39是一种三级页表机制,支持39位的虚拟地址空间(最大支持512GB的虚拟内存),这39位的虚拟地址又分为以下5部分:
保留区:25位
页内偏移(12位):4KB 页大小(4096 字节)
三级页表索引(各 9 位):
- L2 Page Directory Index(Page Directory指的是多级页表中的某一级页表)
- L1 Page Directory Index
- L0 Page Directory Index
我们看到的虚拟地址通常是64位,因为XV6是在RV64的板子上的,但是虚拟地址实际上只有低39位有效
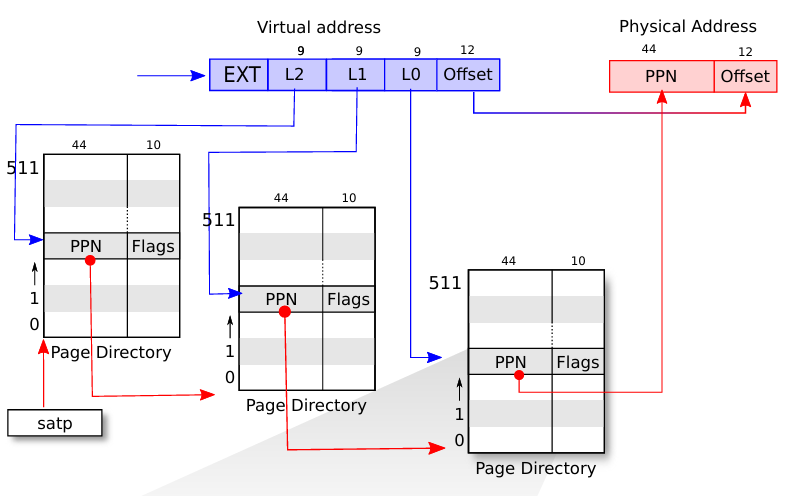
虚拟地址->物理地址的翻译过程:
首先MMU根据
satp获得L2 Page Directory的物理地址,然后根据虚拟地址的L2 Index从中找出对应的PTE2,该PTE保存了L1 Page Directory的物理地址(PPN)接着从物理内存中找到L1 Page Directory,并结合L1 Index从中找出对应的PTE1,该PTE保存了L0 Page Directory的物理地址
接着从物理内存中找到L0 Page Directory,并结合L0 Index从中找出对应的PTE0,该PTE保存了目标物理页的地址,并结合虚拟地址的低12位获得页内偏移,最终得到完整的物理地址
“虚拟地址->物理地址的翻译”是MMU硬件帮我们完成的,但是XV6实现了一个函数walk()来软件模拟这个过程,因为有的时候内核中要访问用户空间(比如copy_in()),而此时satp寄存器里设置的是内核页表,所以就需要一个函数能够在内核中实现用户页表的地址翻译
1 | pte_t *walk(pagetable_t pagetable, uint64 va, int alloc) |
物理地址结构
如上图右侧,RISC-V的物理地址为56位,分为以下3部分:
保留区:8位
物理页号(PPN):高44位
页内偏移(offset):低12位(待访问字节位于一页的哪里,其实很好理解,一页为4096字节=2^12)
我们看到的物理地址通常是64位,因为XV6是在RV64的板子上的,但是实际上只有低56位有效
这样的分法是OS和MMU决定的,物理内存实际上并没有分页,直接按字节访问
PTE结构
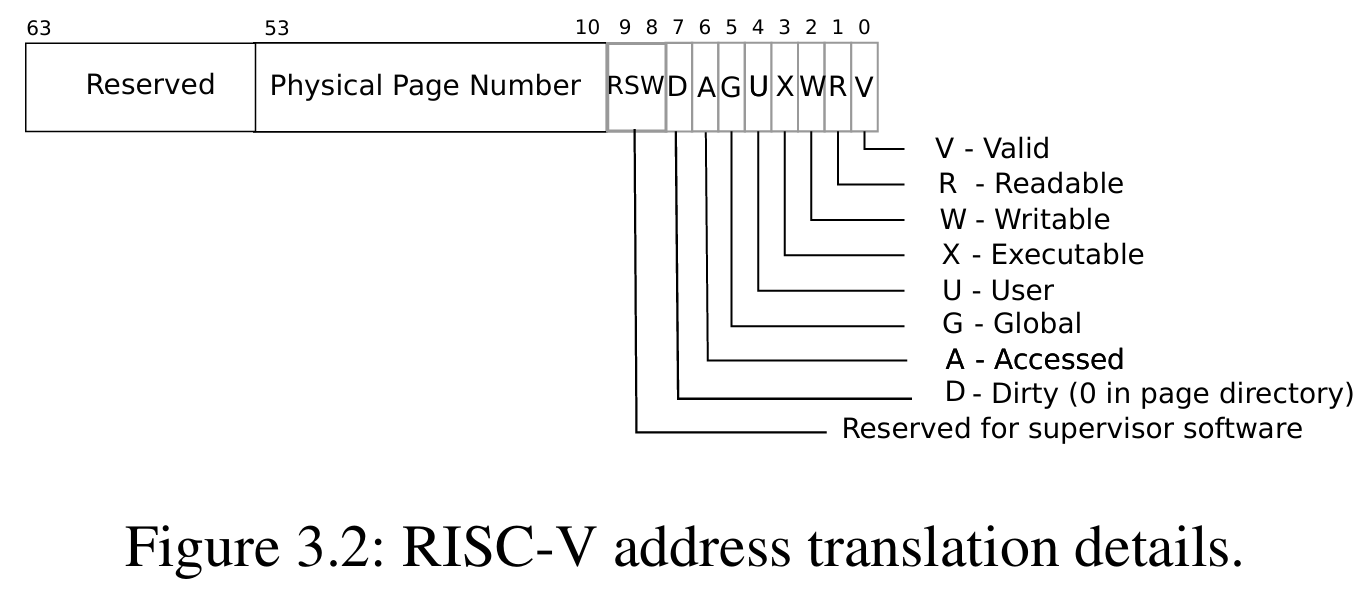
PTE是Page Directory中的一项,每个PTE占用64位,主要分为以下3部分:
- 保留区[63:53]:10位
- 物理页号(PPN)[53:10]:44位,通过左移再补12位的0(页内偏移)组成实际的物理地址
- 标志位[9:0]:10位
| 位 | 名称 | 功能描述 |
|---|---|---|
| 0 | V (Valid) | 页表项是否有效。1=有效,0=无效(访问会触发缺页异常) |
| 1 | R (Read) | 是否可读。1=允许读取该页数据 |
| 2 | W (Write) | 是否可写。1=允许写入该页(必须R=1才能设置W=1) |
| 3 | X (Execute) | 是否可执行。1=允许执行该页代码(通常不与W同时设置,防止代码注入攻击) |
| 4 | U (User) | 用户权限。1=用户态可访问,0=仅内核态访问(用于内核隔离) |
| 5 | G (Global) | 全局页。1=TLB全局缓存(所有进程共享,如内核代码),0=仅当前进程有效 |
| 6 | A (Accessed) | 访问标记。1=该页曾被访问(用于页面置换算法),由MMU自动设置 |
| 7 | D (Dirty) | 脏页标记。1=该页曾被修改(mmap需写回磁盘时使用),由MMU自动设置 |
| 8-9 | Reserved | 保留位(为内核的一些自定义功能保留) |
- A、D标志位由CPU自己维护,比如它可能会每100ms就清空所有PTE的该标志位,如果某个PTE又把它置1了,就说明最近访问过
PTE的标志位有什么用?
- RWX:表明此页表项的读写权限
- V:检测物理页是否被分配从而触发缺页异常
- A:用于页面置换的控制
- D:用于写回磁盘的控制
页表缓存(TLB)
由于每次将一个虚拟地址转换成物理地址需要3次查表(Sv39中),非常浪费时间,所以CPU内置了一个硬件用于对最近访问过的PTE进行缓存,在访问MMU之前,CPU会先访问TLB,查看是否要访问的虚拟地址已经被缓存了
何时清空?
在切换页表时,必须清空TLB,在RISC-V中是sfence.vma指令
Page Fault
概述
Page Fault(缺页异常)是一种由MMU引发的异常,对于在trap handler中对Page Fault进处理,是OS的重要工作之一。通过对Page Fault的合理应用,OS可以实现非常多有用的特性,从而优化OS的性能,比如Lazy Allocation、COW、mmap…(虽然XV6一个都没实现…)
触发Page Fault时内核需要的信息:
- 引起page fault的虚拟地址(会被存到
STVAL寄存器中) - 引起page fault的原因(load/store/jump,会被存到
SCAUSE寄存器中) - 引起page fault的
pc计数器值(会被存到SEPC寄存器中)
Page Fault的分类
根据访问的虚拟地址的合法性,Page Fault可分为以下2类:
(1)合法访问:当程序访问的虚拟内存地址有效,但对应的物理页面尚未加载到内存时,会触发合法的 Page Fault,操作系统会自动处理,并返回发生异常的地方重新执行,常见场景包括:
- 首次访问未分配的页面
- 程序刚申请内存(如
malloc),但尚未实际读写,操作系统采用惰性分配策略,首次访问时才分配物理页
- 程序刚申请内存(如
- 页面被换出到磁盘(Swap/Pagefile)
- 物理内存不足时,操作系统将不活跃的页面换出到磁盘(交换空间)。再次访问这些页面时,需从磁盘换回内存
- 内存映射文件(Memory-Mapped File)
- 通过
mmap映射的文件,首次访问某部分内容时,需从磁盘加载对应数据到内存
- 通过
- 写时复制(Copy-on-Write, COW)
- 进程调用
fork()创建子进程时,父子进程共享只读页面。当某进程尝试写入时,触发 COW 机制,复制新页面并修改权限
- 进程调用
(2)非法访问:当程序访问无效或受保护的地址时,会触发非法 Page Fault,通常导致程序崩溃(如段错误)。原因包括:
- 访问无效的虚拟地址
- 解引用空指针(
NULL)、访问已释放的内存(悬垂指针)或越界访问数组
- 解引用空指针(
- 权限冲突
- 尝试写入只读页面(如代码段或 COW 页面未正确处理)
- 用户态程序访问内核态内存(如系统调用未正确传参)
- 地址空间切换问题
- 多线程/多进程环境下,某线程访问了其他进程的地址空间(如线程同步失败)
Copy On Write fork
xv6在执行fork系统调用时,子进程会拷贝一份父进程的页表,并在物理内存上分配对应的内存。这样做有很大的缺点:
- 速度很慢,导致父进程长时间阻塞
- 如果子进程执行
exec,则从父进程拷贝来的很多内存都会被释放,就白拷贝了
因此,现代OS在实现fork时,大多会实现一种“写时拷贝”的fork:
当父进程通过 fork() 创建子进程后,子进程会复制一份父进程的页表。父进程和子进程的页表会共享相同的物理内存页面,但这些共享的页面会被标记为只读。这就实现了:在没有写操作时可以共享物理内存,从而节省内存资源。但当父进程或子进程中的某个进程尝试写入这些页面时,会触发页面错误(page fault)异常并使内核对此进程进行如下操作:
- 分配新的物理页面。
- 将原始页面的内容复制到新页面。
- 更新写入方的页表映射,使其指向新的物理页面并标记为可写。
这种方式保证了写入后的页面不会影响到另一个进程,实现了写入时复制的效果
sbrk
首先要知道一点kalloc, malloc之类的API并不是系统调用,而是C的库函数,在XV6中,对内存中的堆区大小做动态管理的系统调用是sbrk(),通过传入的参数,该接口会动态地调整堆区的大小(XV6进程的数据结构中,会有一个变量存储:当前堆区顶部的虚拟地址(初始值为stack顶的虚拟地址)p->sz),并分配物理内存。在XV6中,这个系统调用是eager allocation
Lazy Allocation
定义:当用户在堆区分配内存时,OS并不会立即分配物理内存和创建相应的页表项、只是改变了p->sz的大小。当访问这些新的虚拟内存时,触发一个page fault,并在trap handler中分别物理内存和新建页表项及映射
优点:
- 内存节省:如果分配的内存最终未被访问,物理内存将不被使用,避免浪费
- 提高性能:延迟分配可以减少不必要的内存分配操作,特别适用于大量内存申请但部分或不使用的场景。
- 提升初始化效率:减少初始化时的内存分配时间,因为系统只分配虚拟内存地址,而不做物理内存映射
缺点:
- 该方法导致了page fault的额外开销,包括了用户态/内核态的切换
Demand Paging
定义:操作系统在新创建一个进程时,不是一开始就在物理内存中分配这个进程所需要的总大小,而是在首次访问到某个数据时,触发一个page fault,再在物理内存中进行分配内存,并将对应的数据从磁盘加载到物理内存中
- 优点:节省了内存消耗,并提高了进程的启动速度
- 缺点:需要多次从磁盘读取数据,速度较慢;增加了page fault的处理时间
哪些数据是在进程初始化的时候不分配物理内存的呢?
- 程序的BSS段(未初始化数据段),该段内存中存储了未初始化的静态变量和全局变量。进程刚启动时,page table会将BSS段的所有虚拟地址映射到同一个PA,并设置PTE对应的标志位,在真正访问这些PTE时,才会触发Page Fault进而分配物理内存和修改PTE
- Text和Data段,分别存储了代码指令和有初始值的静态遍历和全局变量,会为他们创建PTE但是标志位为invalid,当访问到这些PTE时会触发Page Fault,分配物理内存并从磁盘中加载数据进去
页面置换
定义:OS是会使用大于实际物理内存大小的内存,因此页表中只有一部分的数据实际是存在RAM中的,另一部分是在磁盘的交换空间中,并且这些数据对应的页表项的”V“标志位被设置为0,当访问这些页表项时,会触发page fault,此时再为这些数据分配物理内存,并修改PTE的映射。但有的时候物理内存已经没有多余空间了,此时内核会将某个PTE的在物理内存中的数据转移到磁盘交换空间中,并修改其V标志位,以此来获得多余的物理内存空间
当内存满了时,会把哪些页面的内存撤回呢?
这其实就是跟缓存满了,新的缓存放到哪是一个问题,本质就是在问有哪些页面替换策略,比如:
- LRU:释放最近没被访问过的内存,通过PTE标志位的“Access”位来判断该内存最近是否被访问过,该bit每隔一段时间就会被刷新一次
Memory Mapped Files
当我们需要在用户空间中修改一个文件的时候,可以使用mmap()来把加载到内核空间的磁盘文件直接映射到用户空间,从而避免数据的在用户空间和内核空间之间的数据拷贝
在使用外设时也会用到,因为Linux下一切皆文件,设备也是一种文件
在内核实现mmap时,也可以利用Page Fault机制:mmap 在将文件或匿名内存映射到用户空间的虚拟地址空间时,不会立即分配物理内存或加载文件数据,而是依赖后续的Page Fault动态加载
现代OS通常提供mmap(va,len,perm,flag,fd,offset...)系统调用来实现此功能
当操作完成时,使用unmap(va,len..)会从页表中删除这些页的映射,OS会在后台把PTE中dirty bit被置位的页给写会磁盘
物理内存的分配与回收
XV6对于物理内存以页为单位进行管理,它并没有像Linux那样使用伙伴算法来减少内存页间的碎片,而是使用简单的“首次适应”算法分配物理页
它在内核中维护了一个空闲页的链表kmem,在系统初始化的时候被创建,并把内存中所有空闲的物理页的地址都保存在里面。其中每个空闲页的前八个字节是个指针,指向了下一个空闲页的地址。XV6对于物理内存的管理实际上就是对于该链表的增/删操作。
首次适应算法(First-Fit) 是一种内存分配策略,主要用于管理空闲内存块。它的核心思想是:从内存的起始地址开始顺序搜索,找到第一个能满足请求大小的空闲块,立即分配
除了First-Fit,还有很多别的物理内存管理算法:
| 算法名称 | 工作原理 | 优点 | 缺点 | 应用场景 |
|---|---|---|---|---|
| 首次适应 (First Fit) | 从空闲链表头部开始查找,分配第一个满足大小的空闲块 | 分配速度快,实现简单 | 容易产生外部碎片 | FreeRTOS heap_2.c |
| 最佳匹配 (Best Fit) | 遍历整个空闲链表,分配能满足需求的最小空闲块 | 内存利用率较高 | 速度慢,可能产生微小碎片 | FreeRTOS heap_4.c |
| 最差匹配 (Worst Fit) | 总是分配最大的空闲块 | 减少微小碎片产生 | 大块内存容易被拆分 | 特殊场景(如长期运行的大块分配) |
| 伙伴系统 (Buddy System) | 将内存划分为2的幂次方大小块,合并时只能与“伙伴”合并 | 碎片少,合并效率高 | 内存浪费(内部碎片) | Linux 内核物理内存管理 |
| 分离空闲链表 (Segregated Free Lists) | 按大小分类维护多个空闲链表(如 16B、32B、64B…) | 分配速度快,减少搜索时间 | 需要预分配固定大小分类 | TLSF(实时内存分配器) |
XV6中内存相关的函数
物理内存分配与回收
1 | /* kalloc.c */ |
虚拟内存映射
1 | /* vm.c */ |
参考链接
7.进程管理
任务模型
从XV6或Linux内核的视角,进程和线程并没有区别,因为它们在内核的中的调度和管理方式是一致的。它们的区别主要在于资源的管理方式,后面用任务统称进程和线程
- 线程的定义:单个串行执行代码的单元,是CPU调度的基本单位
- 线程在切换时需要保存一些上下文:
- PC指针
- CPU寄存器
- 栈区(每个线程都有自己的栈区,各线程的栈的大小一般都是固定的。各进程的栈实际上都是被各个线程给分成了多份的)
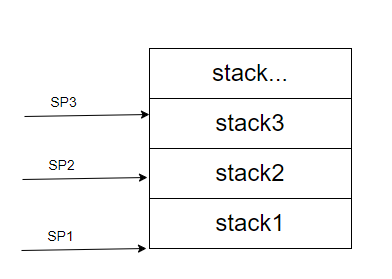
XV6中有2类线程:
- 内核线程:每个用户线程都有一个内核线程来执行其发起的系统调用,而各内核线程都使用内核的页表,所以它们共享同一个内存空间
- 用户线程:由于XV6中每个进程都有自己独立的页表,所以不同进程的用户线程之间是独立的
XV6与Linux的一样,一个用户线程对应一个内核线程,不是一对多或者多对多的关系。而且不是所有内核线程都有对应的用户线程,有的线程只运行与内核态,比如调度器线程
任务的状态
XV6的任务分为以下几种状态:
- Running:正在CPU上运行,此时线程的PC指针、寄存器位于CPU中
- Runnable:能够在CPU上运行,但还没得到CPU的控制权,此时线程的PC指针、寄存器位于RAM中
- Sleeping:正在等待I/O操作完成,此时并不想得到CPU控制权
- Zombie:结束运行但是没有被释放资源
任务调度
定义:停止一个线程的运行并启动另一个线程的运行
XV6为每个CPU核都创建了一个线程调度器(scheduler)
常见调度策略:指 “选择下一个运行任务的规则”
| 调度策略 | 类型 | 核心思想 | 优点 | 缺点 | 典型应用场景 |
|---|---|---|---|---|---|
| 先来先服务 (FCFS) | 批处理 | 按任务到达顺序执行 | 简单、无饥饿问题 | 护航效应(长任务阻塞短任务) | 早期批处理系统 |
| 时间片轮转 (RR) | 交互式 | 每个任务分配固定时间片(如 10ms),超时后放入队列尾部 | 公平性高,响应时间可控 | 时间片设置影响性能(太小增加开销) | 通用操作系统(如 Linux 默认) |
| 多级反馈队列 (MLFQ) | 交互式 | 多级优先级队列,任务根据行为动态升降级(如 I/O 密集型升优先级) | 平衡响应时间和吞吐量 | 实现复杂,需调优参数 | 混合负载(如服务器、桌面 OS) |
| 完全公平调度 (CFS) | 公平共享 | 按权重(nice 值)分配 CPU,通过红黑树管理任务的虚拟运行时间(vruntime) |
高公平性,支持多任务并发 | 实时任务需额外策略(如 SCHED_FIFO) |
Linux 默认调度器 |
| 最早截止时间优先 (EDF) | 实时 | 优先执行截止时间最近的任务 | 满足硬实时需求,理论最优 | 需严格的任务时间约束 | 工业控制、自动驾驶 |
调度策略的实现方式:指 “如何在代码中具体触发调度策略”
- 抢占式任务调度:每隔一段时间,内核会抢占当前运行任务的CPU控制权,并把控制权给另一个任务,触发条件包括:
- 时间片用完(如 Linux CFS 的
sched_yield) - 更高优先级任务就绪(如实时任务)
- 中断或系统调用返回时(如时钟中断触发调度)
- 时间片用完(如 Linux CFS 的
- 协作式任务调度:当前运行任务一直拥有CPU控制权,直到它主动放弃,触发条件包括:
- 任务显式调用阻塞函数(如
sleep()、pthread_yield()) - 任务等待 I/O 或同步事件(如锁、信号量)
- 任务显式调用阻塞函数(如
XV6使用了==时间片轮转==调度策略,并通过==抢占式==调度触发
任务切换的流程:
每个CPU会定时产生一个定时器中断,从而让一个用户线程陷入内核中(由用户线程切换到内核线程),让CPU的控制权由用户线程变为内核。在内核线程的中断处理函数中,通过yeild主动让出此CPU给调度器线程(每个CPU都有个调度器线程),从而发生调度。此时CPU的控制权会先变到另一个内核线程,再变到该内核线程对应的用户线程
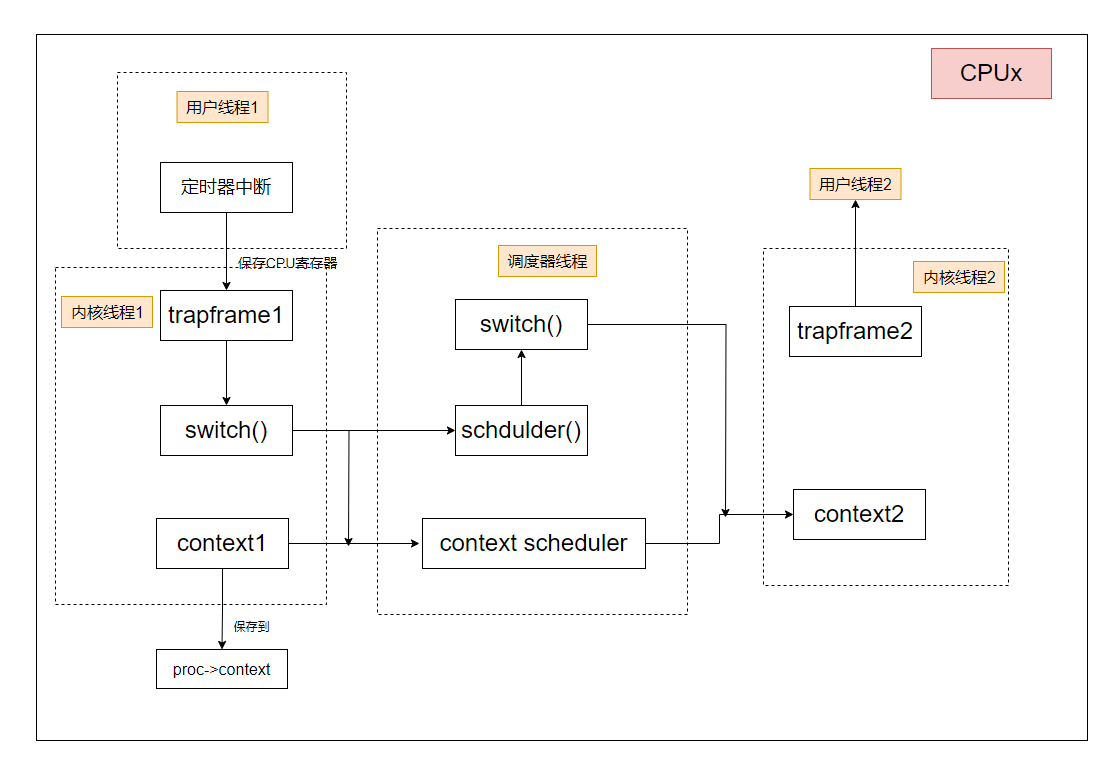
- trampframe:保存用户线程CPU的寄存器
- context:保存内核线程CPU的寄存器
睡眠与唤醒
用户态与内核中使用睡眠函数的区别:
- 用户态:让一个线程睡眠后,可以不手动唤醒,比如在使用
sleep(int time)时让线程睡眠指定的一段时间,时间到了后OS会自动唤醒一个线程。但是当使用条件变量而让线程睡眠时pthread_cond_wait,在条件满足时,需要手动唤醒睡眠的线程pthread_cond_signal - 内核态:让一个线程睡眠
sleep()后,必须手动唤醒wakeup()
进程的退出和资源回收
- 手动结束一个进程的方法:使用
exit()系统调用 - 普通结束的方法:
main()函数的return 0
无论子进程是通过
exit退出,还是通过return退出main函数,都会最终调用内核的_exit函数以结束进程
注意,任何一个进程都属于一个父进程,当子进程退出时,它自己不会释放资源,并变为Zombie状态,需要父进程调用wait()系统调用,来回收子进程的资源
wait()系统调用有点类似C++11线程库的join(),用于阻塞等待子进程的退出,并回收其资源
僵尸进程:已经终止运行但还未被父进程回收的进程
如果一个进程结束前它的父进程就结束了,父进程在结束前会把它的子进程的所有权转给init进程,由它帮忙回收子进程的资源
8.进程间通信/同步/互斥
概念的区别
| 概念 | 核心目标 | 典型场景 | 实现方式 |
|---|---|---|---|
| 通信 | 进程间数据交换 | 传递消息或共享数据(如管道、共享内存) | 管道、消息队列、共享内存、Socket等 |
| 同步 | 协调进程的执行顺序 | 确保某些操作按特定顺序执行(如A完成后B再执行) | 信号量、条件变量、屏障(Barrier)等 |
| 互斥 | 保护共享资源,避免并发访问冲突 | 临界区(如共享文件、内存的原子操作) | 互斥锁、信号量(二元信号量)、自旋锁等 |
同步和互斥的区别:举“生产者-消费者”的例子,如果同时存在多个生产者线程同时往buffer中写数据,则属于互斥问题;当缓冲区为空的时候,需要生产者先往buffer中写数据,消费者才能读数据,属于同步问题
联系
- 互斥是同步的一种特例:互斥通过限制共享资源的访问顺序实现同步,属于同步的子集
- 进程间的通信可能依赖同步/互斥机制:例如,共享内存通信需要互斥机制(如锁)保护数据一致性;消息队列本身可能内置同步(阻塞发送/接收)
- 同步/互斥的实现依赖底层通信:某些同步机制(如信号量)可能通过内核提供的IPC机制实现
死锁
定义:两个或多个事务在同一资源上相互占用,并请求锁定对方的资源,从而导致恶性循环的现象
出现场景:
1.一个线程中在未释放的情况下多次请求同一个锁
2.由获取锁的顺序导致死锁:线程1需要依次获取锁A和B,线程2需要依次获取锁B和A,这会导致死锁
锁的分类
按锁的实现原理分类:
(1) 互斥锁(睡眠锁)
- 特点:最基本的锁,保证同一时间只有一个线程能进入临界区
- 行为:未获取锁的线程会被阻塞(进入休眠状态)
- 示例:
pthread_mutex_t(POSIX)、std::mutex(C++)
(2) 自旋锁
- 特点:通过循环忙等待(Busy-Waiting)尝试获取锁,而非阻塞线程
- 适用场景:临界区非常小且线程阻塞代价较高(如内核态代码)
- 缺点:浪费CPU资源
- 示例:
pthread_spinlock_t、std::atomic_flag(C++自旋锁实现)
(3) 读写锁
- 特点:区分读锁(共享)和写锁(独占),提高读多写少场景的性能
- 读锁:允许多个线程同时读
- 写锁:只允许一个线程写,且与读锁互斥
自旋锁的实现
一般人可能一下子就想到了用这种错误的方式实现:
1 | void acquire(struct spinlock *lk) |
这种实现在获得锁的时候还是会存在竞争,比如2个CPU可能会同时拿到锁(本质上因为CPU的load和store指令是非原子的)因此在判断能不能拿到锁的时候,应该原子操作指令
在XV6中它的锁的实现是靠TAS这个原子操作来实现的,并且还需要考虑内存顺序的问题
1 | void acquire(struct spinlock *lk) |
原子操作
原子操作属于ISA提供的CPU指令,对于RISC-V来说,A指令集模块提供了一些原子操作指令。C++标准库的锁、原子变量的底层实现都依赖这些指令。如果所使用的内核不带A指令集,那他就没办法使用这些同步机制了
常见的原子操作如下:
- CAS(Compare-And-Swap)比较内存值和预期值,如果相等则更新为新值,否则失败
- TAS(Test-And-Set)读取内存值并强制设置为新值(通常用于锁标志)返回旧值
- FAA(Fetch-And-Add)原子地读取内存值并增加一个数值,返回旧值
内存顺序
现代 CPU 和编译器会对指令进行乱序执行以提高性能,但在多线程环境下,这可能导致数据不一致。
内存顺序用于控制这种乱序行为,确保线程间的数据同步
CPU底层通常会提供一些“内存屏障”指令,用来控制指令执行顺序和内存访问的可见性,RISC-V 提供了 FENCE 指令,用于控制内存访问顺序,语法如下:
1 | FENCE pred, succ |
pred(前驱操作):可以是R(Read)、W(Write)、RW(Read+Write)succ(后继操作):同上,表示FENCE之后的操作必须等待前面的操作完成
内存屏障的应用:
(1)锁的底层实现:
- 加锁(Lock):确保临界区内的操作不会被重排序到加锁之前
- 解锁(Unlock):确保临界区内的操作不会被重排序到解锁之后
(2)无锁编程:如果临界区极短、追求极致性能时,可以使用内存屏障来实现临界区的互斥访问,并不需要用锁
无锁同步机制
RCU
RCU(Read-Copy-Update)是一种不需要锁的同步机制,主要用于解决多线程环境中读多写少场景下的性能问题。它通过无锁读取和延迟更新显著提升并发效率,核心思想:
- 读者无锁访问:读取数据时无需加锁,直接访问共享资源,保证高性能,但在临界区内需要禁止调度
- 写者延迟更新:写入时先创建数据的副本,修改副本后通过原子操作替换原数据,并通过内存屏障机制(
synchronize_rcu)等待所有旧读者退出后再回收旧数据
虽然RCU和读写锁都用于“读多写少”的场景,但是RCU的读写不互斥,且读写锁底层要解决缓存一致性问题,效率比较低
| 场景 | RCU | 传统锁(如互斥锁) |
|---|---|---|
| 读者 | 无锁,直接访问 | 需加锁,可能阻塞或被阻塞 |
| 写者 | 无锁发布数据,宽限期异步回收 | 需独占锁,阻塞其他读写者 |
| 并发性 | 读者与读者、读者与写者完全并发 | 读写互斥,串行化访问 |
RCU的缺点:
- 无法保证读/写数据完全同步,在
synchronize_rcu前进入临界区的读者会读到旧数据 - 若多个写者并发修改同一数据,仍需外部锁(如自旋锁),这会部分抵消 RCU 的优势
9.文件系统
文件系统目的:将所有数据结构以一种能够在重启之后重新构建文件系统的方式,存放在磁盘上。不同的文件系统在磁盘上的布局不同
磁盘读写粒度
- Sector:磁盘硬件的最小读写单元,通常为512B
- Block:文件系统管理磁盘的最小逻辑单元,通常为4KB(与内存页对齐),XV6中是1024 B
XV6文件系统的分层
- 在最底层是磁盘,也就是一些实际保存数据的存储设备,正是这些设备提供了持久化存储
- 在这之上是buffer cache或者说block cache,这些cache可以避免频繁的读写磁盘。这里我们将磁盘中的数据保存在了内存中
- 为了保证持久性,再往上通常会有一个logging层。许多文件系统都有某种形式的logging
- 在logging层之上,XV6有inode cache,这主要是为了同步(synchronization)inode通常小于一个disk block,所以多个inode通常会打包存储在一个disk block中。为了向单个inode提供同步操作,XV6维护了inode cache
- 再往上就是inode本身了。它实现了read/write
- 再往上,就是文件名,和文件描述符操作
磁盘布局
XV6文件系统在磁盘上以如下的方式布局:
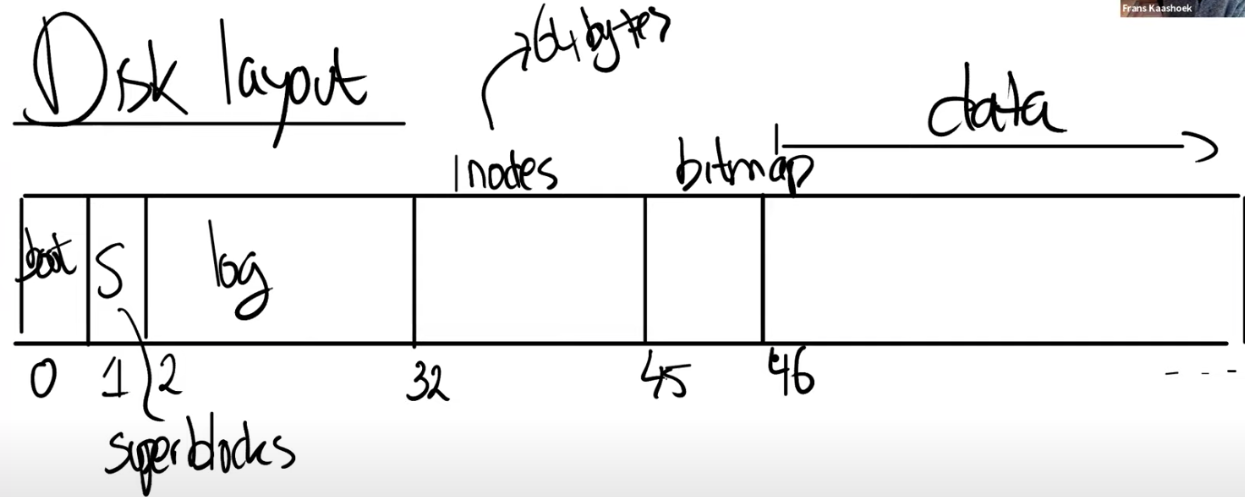
- block0要么没有用,要么被用作boot sector来启动操作系统
- block1:super block,它描述了文件系统。它可能包含磁盘上有多少个block共同构成了文件系统这样的信息。我们之后会看到XV6在里面会存更多的信息,你可以通过block1构造出大部分的文件系统信息
- block2~block32:存log信息。实际上log的大小可能不同,这里在super block中会定义log就是30个block
- block32~block45:存储inode。多个inode会打包存在一个block中,一个inode是64字节,即一个block只能存16个inode,XV6最多能存16*14=224个文件/目录
- bitmap block:只占据一个block。它记录了各个数据block是否空闲
- 数据block:存储文件的内容和目录的内容
通常来说,bitmap block,inode blocks和log blocks被统称为metadata block。它们虽然不存储实际的数据,但是它们存储了能帮助文件系统完成工作的元数据
inode
inode是所有文件系统都会有的一个数据结构,他记录了磁盘中某个文件的一些属性信息。XV6中的inode的数据结构如下:
1 | // in-memory copy of an inode |
inode不仅会在内存中,他本身也会存在磁盘中!并且在不同位置时包含的字段还不一样
关键字段:
- type:表明inode是文件还是目录。
- nlink:也就是link计数器,用来跟踪究竟有多少文件名指向了当前的inode。
- size:表明了文件数据有多少个字节。
- addrs:一个数组,存了inode对应文件的各个磁盘block的编号(XV6中每个inode有12个direct block和256个indirect block,所以一个文件最大占268*1024字节)
有了inode其实就可以实现
read/write系统调用了
目录
目录也是一种文件,他的数据部分包含了多个==目录项==(direct entry)数据结构。XV6中每一个目录项的组成如下:
- 前2个字节包含了目录中文件或者子目录的inode编号
- 接下来的14个字节包含了该目录项对应的文件或者子目录的名字
有了目录,OS就能实现结构化命名和根据文件名查找文件了,原理其实就是从根目录开始查找所有目录项的name字段,看看是否匹配
文件系统镜像
XV6的文件系统实际上是挂载的fs.img这个文件,而每次make qemu时,都会由mkfs这个可执行文件重新构建fs.img。它的布局就跟上面说的一样

BufferCache
之前看Linux源码解析的时候,发现OS里面居然有cache部分还很有疑问,一直以为cache只存在于CPU硬件中,实际上OS里确实会有cache,这部分cache用于把磁盘的东西缓存到内存里面。而基于缓存的粒度,对磁盘的缓存可以分为:
- buffer cache:对磁盘块缓存(XV6只有这种)
- page cache:对文件进行缓存(以page为单位)
当第一次对磁盘进行IO操作读数据的时候,回把从磁盘读到的数据存到OS的cache(内存)里,后续再对磁盘进行IO操作时,首先会看cache里有没有缓存对应的块,有的话就只会操作这个cache,最后结束对此块的IO操作时,再把cache里的数据flush回磁盘,其实跟CPU里的cache如出一辙


