03 计算机组成原理
计算机组成原理
计算机的基本组成
如果找来一本计组的书,或者看一些博客,他们通常会告诉我们,计算机包含五个核心的模块:输入设备、输出设备、存储器、运算器、控制器。这虽然没错,但是是一种以比较高层的视角来看的,为了更清晰地了解其中的细节,本文从微架构的角度,更深入的分析一台计算机的组成
CPU
在计算机系统中,CPU是负责执行指令、驱动整个系统运行的核心部件。如果仅从功能上看,CPU无非是在做三件事:取指、运算、访存。一般的教材里会告诉我们,CPU主要包含计算单元、控制单元、寄存器3类模块,在现代处理器中,为了在有限的频率和功耗下获得更高的性能,CPU的内部结构已经演化得非常复杂。计算单元、控制单元内部也包含了很多模块,不仅仅是一个独立的东西了
指令的执行
从一种简化的角度看,一条指令的执行可以拆解为以下几个阶段:
- 取指(Fetch):根据当前程序计数器(PC),从指令存储器或指令缓存中取出指令
- 译码(Decode):分析指令的操作类型、源操作数、目标寄存器等信息,并生成后续执行所需的控制信息
- 执行(Execute):在执行单元中完成算术运算、逻辑运算或地址计算
- 访存(Memory Access):对于Load/Store指令,通过访存单元访问数据缓存或内存系统
- 写回(Write Back):将执行结果写回寄存器,供后续指令使用
早期处理器通常严格按照这一顺序、一次只执行一条指令。现代CPU则通过流水线和并行机制,让多条指令在不同阶段同时推进
流水线的基本思想是:把一条指令的执行过程拆成多个阶段,让不同指令在不同阶段并行执行
流水线能并行的前提是:每个阶段都有独立的硬件来执行。在应用层开发时也有流水线的概念,但是如果要做到真正的并行,得有多个CPU核一样
一个经典的流水线可能只有五级,包括上面提到那5个步骤
在理想情况下,当流水线填满后,CPU可以做到每个时钟周期完成一条指令,而不是原始的5个时钟周期才能完成一条指令,显著提高吞吐率
但流水线也会引入新的问题:
- 结构冒险:多个阶段竞争同一硬件资源
- 数据冒险:指令之间存在数据依赖
- 控制冒险:分支指令导致取指方向不确定
现代CPU通过转发、暂停、分支预测等手段来缓解这些问题,且流水线通常有10级以上,远远不仅仅是上面提到的5个简单的步骤
微架构层次
可以从一条指令被执行的路径,将CPU划分成不同的功能模块
前端
前端的职责是持续、稳定地向后端提供指令。它并不真正“执行”指令,而是决定接下来要执行哪些指令
前端通常包括以下功能模块:
- 指令缓存(I-Cache):为取指提供低延迟的指令存储
- 取指单元(IFU):根据当前程序计数器获取指令流
- 分支预测单元(BPU):预测控制流走向,减少控制冒险带来的停顿
- 译码单元(IDU):将指令转换为CPU内部可调度的形式
前端性能的瓶颈往往不在于“算得快不快”,而在于:
- 是否能提供足够高的指令带宽
- 分支预测是否足够准确
一旦前端供给不足,后端即使具备强大的并行执行能力,也会因为“吃不饱”而空转
调度与发射
调度与发射位于前端和执行单元之间,是现代CPU中最具“智能性”的部分
在这一层,指令已经完成译码和寄存器重命名,并进入调度队列。硬件会持续检查这些指令的状态,包括:
- 源操作数是否就绪
- 所需执行单元是否空闲
- 是否存在结构或资源冲突
调度(Scheduling)的职责是:在大量候选指令中,找出当前“可以执行”的指令
发射(Issue)的职责是:将这些已就绪的指令,在同一个时钟周期内,派送到对应的执行单元中
- 在支持超标量的CPU中,调度器可以在一个周期内同时发射多条指令,只要它们之间不存在依赖冲突,并且执行资源允许
- 发射并不意味着指令立刻执行完成,而是表示指令正式进入执行流水线
后端
后端是CPU中真正完成计算和访存操作的部分。它由多个并行存在的执行单元组成,不同类型的指令会被送往不同的执行通路
常见的后端执行单元包括:
- 整型单元(IU):算术逻辑单元(ALU)、乘法单元(MULT)、除法单元(DIV)和跳转单元(BJU)…
- 浮点单元(FPU):浮点算术逻辑单元(FALU)、浮点乘累加单元(FMAU)、浮点除法开方单元(FDSU)…
- 矢量单元(VU):矢量加法单元(VALU)、矢量移位单元(VSHIFT)、矢量乘法单元(VMUL)、矢量除法
单元(VDIVU)、矢量置换单元(VPERM)、矢量缩减单元(VREDU)、矢量逻辑操作单元(VMISC)… - 访存单元(Load / Store Unit):地址计算与内存访问
后端执行通常是乱序进行的,即指令可以不按照程序顺序完成执行,只要不违反数据依赖关系即可。这种乱序性是隐藏访存延迟、提高执行单元利用率的关键手段。
一个CPU中通常会存在多个执行单元,以支持多发射和并行执行。调度器会根据指令类型和执行单元空闲情况,将指令分派到合适的单元中
提交与回退
虽然指令在CPU内部可以乱序执行,但对程序而言,结果必须看起来像是顺序执行的。这一保证由提交与回退机制完成
执行完成的指令会进入提交阶段:
- 按程序顺序提交结果
- 处理异常和中断
- 在分支预测失败时回滚状态
常见的实现方式是使用重排序缓冲区(ROB)或类似结构,当发生异常或分支预测失败时,指令退休单元(RTU)可以丢弃尚未提交的执行结果,并恢复到正确的状态继续执行
性能提升机制
在完成基本的流水线划分之后,CPU性能的进一步提升不再取决于频率的简单提高,而依赖于如何在同一时间内推进更多有意义的工作。现代CPU围绕这一目标,引入了一系列性能提升机制,其中最核心的包括超标量、乱序执行以及寄存器重命名。
超标量
超标量指的是CPU在同一个时钟周期内,能够同时发射多条指令的能力。与只能每周期处理一条指令的标量处理器相比,超标量通过复制执行资源和扩宽调度通路,实现了==指令级的并行==
实现超标量通常需要满足两个条件:
- 硬件中存在多个并行执行单元
- 调度与发射模块能够在同一周期内选择并派发多条指令
需要注意的是,超标量并不保证每个周期都能执行多条指令。其实际效果受到程序中数据依赖、分支结构以及可用执行单元数量的限制。在依赖密集或控制流复杂的代码中,超标量的潜力往往难以完全发挥
从本质上看,超标量解决的是“一拍能干多少活”的问题
乱序执行
- 顺序执行模型中,指令必须严格按照程序顺序进入执行阶段。一旦某条指令因等待数据或访存而停顿,后续所有指令都会被阻塞,从而导致执行单元空闲
- 乱序执行通过打破这一限制,使CPU能够在内部不按程序顺序执行指令。只要指令之间不存在真实的数据依赖关系,并且所需资源可用,后续指令就可以被提前执行,从而隐藏访存延迟,提高整体吞吐率
需要强调的是,乱序执行仅存在于CPU内部,==对软件是完全透明的==。CPU会通过提交阶段确保最终结果与顺序执行的程序语义一致。
从作用上看,乱序执行解决的是“有没有指令可以先做”的问题,是超标量机制能够充分发挥作用的前提
寄存器重命名
在程序中,寄存器数量是有限的,不同指令往往会反复使用相同的寄存器名。这会在硬件中引入大量“假相关”,即指令在语义上并不相关,但因为读写了同一个寄存器而被错误地串行化
寄存器重命名通过将体系结构寄存器映射到更多的物理寄存器,消除了这些假相关。每一条写寄存器的指令都会被分配一个新的物理寄存器,从而使原本可以并行的指令得以同时执行
寄存器重命名并不会改变程序可见的寄存器模型,而只是CPU内部的一种资源管理手段。它是实现乱序执行和高效调度的基础设施之一
从本质上看,寄存器重命名解决的是“哪些相关是真正必须等待的”问题
存储系统
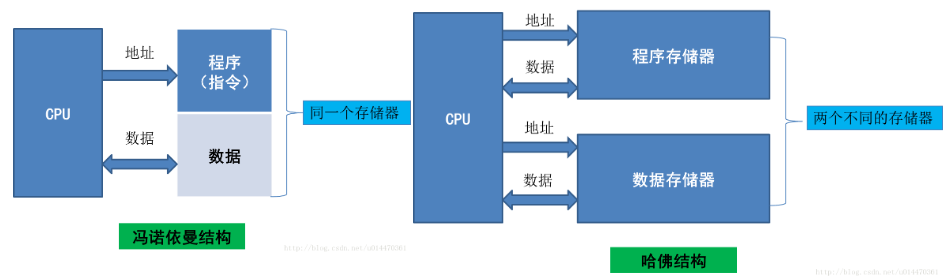
冯诺依曼和哈佛结构
冯诺依曼架构:指令和数据共享同一地址空间、同一存储系统、同一访问路径
哈佛架构:指令和数据在逻辑上分离,有独立的存储和访问路径
| 冯诺依曼 | 哈佛 | 改进的哈佛(现代ARM) | |
|---|---|---|---|
| 数据与程序存储方式 | 存储在一起 | 分开存储 | 分开存储 |
| CPU总线条数 | 1*(地址+数据) | 2*(地址+数据) | 1*(地址+数据)(新增cache,cpu由1条总线读cache,cache有2条总线) |
| 取指操作与取数据操作 | 串行 | 并行,可预取指 | 并行,可预取指 |
| 缺点 | 成本低 | 成本高 | 综合 |
| 优点 | 执行效率低 | 效率高,流水线(取指、译码、执行) | 同哈佛 |
我们之前用的CortexM系列的STM32、8051,其实是属于哈佛架构的,程序和数据分别存在了MCU中的Flash和RAM上
而Cortex A系列的Soc,或者PC上的CPU,一般都是改进哈佛架构的,在CPU外部,程序和数据都存在RAM中,但是在CPU内部又有iROM和iRAM,用于Soc启动时的引导
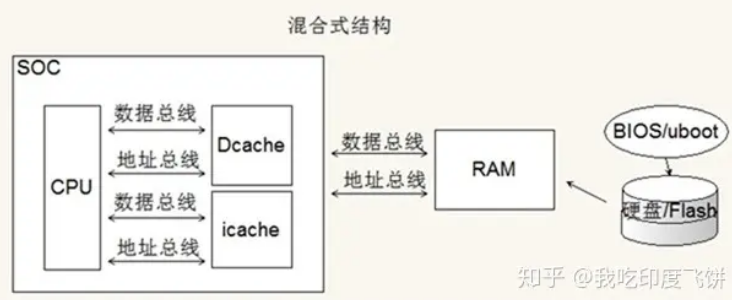
存储系统层次结构
存储器包含以下几种==类别==,不同类别的存储器单字节成本、访问速度都不同
- 寄存器:CPU可直接访问、访问速度最快,差不多等于CPU的时钟周期
- 高速缓冲存储器(Cache):CPU可直接访问,用于存放当前运行程序中的活跃部分,以便快速向CPU提供数据和指令,Cache又分为L1、L2、L3缓存,大小依次增大,速度依次减小
- 主存储器:CPU可直接访问,广义上的运行内存(RAM),用于存放当前运行程序的数据和指令
- 辅助存储器:CPU不可直接访问,用于存放当前暂时不用的程序的数据和指令,用到时再拷贝到RAM中
访问速度:
- Cache:几百到上千GB/s
- 内存:几十GB/s
- 磁盘:几百MB/s
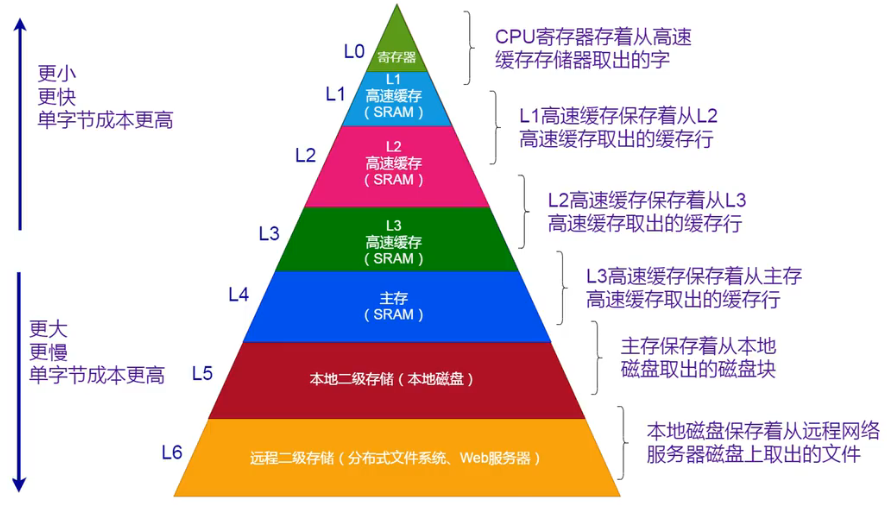
Cache机制
Cache是CPU内部的一种用于临时存储数据的==高速存储器==,目的是减少处理器访问主内存的时间,提高计算机系统的整体性能。一般是SRAM。它位于==处理器和外部RAM之间==
Cache的工作原理其实利用了局部性原理:
- 时间局部性:程序会重复访问最近使用的数据
- 空间局部性:访问某一数据后,附近的数据也有可能被访问
Cache的层次结构
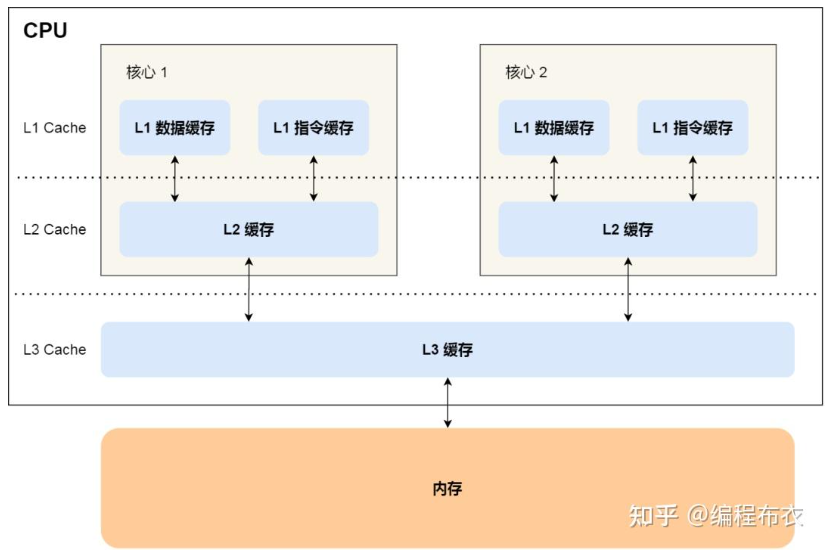
现代CPU中考虑到成本和速度,一般会设置多级缓存:
- L1 Cache:通常位于处理器内核内部,存取速度最快,容量最小。每个处理器核心通常都有独立的L1缓存。又被分为I-Cache和D-Cache
- L2 Cache:一般比L1大,速度稍慢,但仍然比主内存快
- L3 Cache:通常比L2更大且更慢,多个处理器核心可能共享L3缓存
一般一个核内部最多有L1、L2Cache,L3Cache一般多个核共享
Cache line的结构
Cache实际上是由多个Cacheline组成的,Cacheline是CPU从缓存中读写数据的基本单位(一般是多个字节)也是缓存从内存中读取/写入数据的基本单位。
某微架构的Cacheline结构如下:
| Tag (20~40 bits) | State (MESI) | Valid | Dirty | Data |
|---|
| 字段 | 位数 | 作用 |
|---|---|---|
| 标记(Tag) | 20~40位 | 标识该缓存行对应的主存物理地址的高位部分(用于匹配内存块) |
| 状态位 | 2~4位 | 维护缓存一致性协议的状态(如 MESI 中的 Modified/Exclusive/Shared/Invalid) |
| 有效位 | 1位 | 标记该缓存行是否包含有效数据(1=有效,0=无效),CPU能否使用 |
| 脏位 | 1位(可选) | 标记数据是否被相对于内存中的有更新 仅写回策略需要,写直达策略不需要 |
| 数据块 | 64字节(举个例子) | 存储从主存加载的实际数据 |
映射方式
假设我们主存中有32个块,而我们的cache一共有8个cacheline,那么我的第12块内存应该放到Cache中的哪个Cacheline呢?
Cache通过将==内存地址==划分为索引(Index)+ 标记(Tag)+ 偏移(Offset)字段来决定数据映射到哪个Cacheline,具体有三种映射方式:
1.直接映射(Direct mapped):
- 每个主存块只能映射到缓存中唯一固定的位置(类似哈希表)
- 易发生冲突(多个主存块竞争同一缓存行)
2.全相连(Fully associative):
- 主存块可以放在cache的任何位置
- 无冲突,但硬件成本高(需并行比较所有标记)
3.组相连(set associative):
缓存分为多个组(Set),每组包含多路(Way)缓存行。主存块可映射到同一组内的任意行
组号 = (主存地址 / 缓存行大小) % 组数
组内行选择:LRU(最近最少使用)或随机替换
对于一个内存地址长度为32位、Cacheline长度为64为的微架构,其将内存地址进行如下的划分:
1 | | 31 ------- 12 | 11 ----- 6 | 5 -- 0 | |
- Offset(偏移):定位Cache Line内部的具体字节位置。其长度由缓存行数据字段的大小决定(64=2^6)
- Index(索引):用于选择Cache中的一个组(对于组相联Cache)或一个Cacheline(对于直接映射Cache)其长度由Cache中可寻址的组数决定(64组缓存 = 2^6=64 → 6位 Index)
- Tag(标记):用于判断某组缓存中各Cacheline是否与当前给的内存对应。访问Cache时,Index选定候选Cache Line后,Tag字段会与该行中存储的Tag进行比较,以判断是否命中。Tag的长度:为地址中除去Index和Offset后的高位部分(上例中:32 - 6 - 6 = 20位 Tag)
Cacheline访问的流程
- 用输入地址的Index选中一个set
- 取出这个set中所有way的Tag
- 把输入地址中的Tag字段同时与所有way的Tag并行比较
- 如果某一条Cacheline的Tag与输入地址的Tag相等,并且valid位为1,则Cache hit,直接返回数据就行了;反之,如果所有Cacheline的Tag都不匹配,则触发页面替换,选中某个的way进行更新
根据映射所使用的Index和Tag到底是物理地址还是虚拟地址,可以分为以下几类:
- 物理索引物理标记(PIPT):
- 缓存使用物理地址的
Tag|Index|Offset - 优点:无别名问题(多个虚拟地址映射同一物理地址时数据一致)
- 缺点:需先查 TLB(页表)获取物理地址,延迟高
- 缓存使用物理地址的
- 虚拟索引虚拟标记(VIVT):
- 缓存使用虚拟地址的
Tag|Index|Offset - 优点:无需 TLB,速度快
- 缺点:别名问题(需操作系统处理,如页着色)
- 缓存使用虚拟地址的
- 虚拟索引物理标记(VIPT):
Index和Offset用虚拟地址,Tag用物理地址- 折中方案:常见于现代 CPU(如 ARM Cortex-A、Intel/AMD)
写策略
当CPU执行sd指令即往内存中写数据的时候,首先需要对Cache进行写入操作,那Cache何时==把数据真正地写入内存==呢?此时Cache的行为也分为2个类型:
写直达(Write-through):把数据同时写入Cache和内存
- 如果数据已经在 Cache 里面,先将数据更新到 Cache 里面,再写入到内存里面
- 如果数据没有在 Cache 里面,就直接把数据更新到内存里面,再写到Cache里
- 问题:性能低
写回(Write-back):当发生写操作时,新的数据仅仅被写入CacheLine里,只有当修改过的CacheLine「被替换」时才把数据写到内存中
数据已经在 Cache 里面(Tag匹配上了)
- 如果对应CacheLine的dity位=0,则不会写到内存里,只更新Cache里的数据,并更新dity位=1
- 如果对应CacheLine的dity位=1,替换一个CacheLine,并将被替换的CacheLine的数据写回内存,新的数据还是不会写到内存
数据没在 Cache 里面(组里所有Cacheline的Tag都不匹配)
- 使用LRU等策略选择一个被替换的Cacheline进行写入,如果它的dirty=1,则将被替换的Cacheline的数据写回内存
替换策略
当缓存满时,需要决定哪些数据应该被替换掉以腾出空间。这通常通过替换策略来决定,如最近最少使用(LRU,Least Recently Used)、最不常用(LFU,Least Frequently Used)等
Cache一致性
- 定义:在多处理器系统中,确保同一份数据在多个缓存(内存层次)中保持一致的机制
- 如果有人修改了这块数据,而其他设备的缓存还没更新,就会造成“数据不同步”问题,因此需要协议来维护一致性
缓存不一致的原因
- 核间缓存不一致:现代 CPU 采用 多级缓存(L1/L2/L3) 结构,每个核心有独立的 L1/L2 缓存,共享 L3 缓存或主存。当某个核心修改了自己的缓存数据时,其他核心的缓存副本可能仍然是旧值。
- DMA缓存不一致:此外,DMA会绕过CPU直接将外设中的数据写入内存,但CPU中的Cache并未更新,此时CPU可能也会读取到旧值
核间一致性
MESI协议是一种维护多核CPU间的缓存一致性的协议,它通过4种缓存行状态和总线嗅探机制,确保所有核看到的内存数据始终一致
- 总线嗅探机制:某个CPU核心更新了Cache中的数据后,会把该事件广播通过总线通知到其他核心,并且实现了事务串行化
- MESI只用于CPU和CPU之间,不管DMA
- MESI是CPU硬件级的缓存一致性协议,由CPU内部的Cache控制器在总线层自动完成。驱动开发者不需要实现MESI,但需要理解它的原理
1.Cacheline的状态
| 状态 | 含义 | 说明 |
|---|---|---|
| M (Modified) | 已修改 | 缓存行被修改,和内存不一致(只有本核有,脏数据) |
| E (Exclusive) | 独占 | 缓存行未修改,和内存一致(只有本核有,干净数据) |
| S (Shared) | 共享 | 缓存行未修改,和内存一致(多个核都可以有副本) |
| I (Invalid) | 无效 | 缓存行无效(不能用) |
基本思想:
在系统中,任意时刻,同一个物理地址的数据:
- 要么只存在于一个cache,并处于”已修改”或”独占”状态
- 要么存在于多个cache,并处于”共享”状态
- 不可能同时既”已修改”又”共享”(防止不一致)
2.总线事务
多个 CPU 核心共享一条总线。当一个 CPU对cache miss的数据发起访问时,它通过总线发出“请求事务”。其他核通过嗅探(Snooping)监听这些事务,并更新自己的 cache 状态。这就是 MESI 的通信机制
MESI协议定义了以下总线事务
| 名称 | 全称 | 触发原因 | 作用 |
|---|---|---|---|
| BusRd | Bus Read | cache miss(读) | 请求读取一行数据 |
| BusRdX | Bus Read Exclusive | cache miss(写) | 请求读取并获得写权限 |
| BusUpgr | Bus Upgrade | 当前有该行(S),想写 | 请求使其他副本失效 |
| BusWB | Bus Write Back | 驱逐 M 行 | 把脏数据写回内存 |
3.状态转换机制:
(1)读操作
cache hit,且此cacheline是M/E/S状态
- 直接读
cache miss → 发总线事务(BusRd)
- 别的核已缓存该数据:
- 若它是 M:先写回内存(BusWB),然后变为 S
- 若它是 E/S:保持 S,并返回数据
- 本 CPU 拿到数据,也设为 S
- 别的核都没有缓存该数据:
- 内存相应BusRd,取出数据 → 状态为E
- 别的核已缓存该数据:
(2)写操作
- cache hit
- 若本核状态是M:直接写,不发总线事务
- 若状态是E :升级为M,本地写,不发总线事务
- 若状态是S → 发出BusUpgr,使其他核对应 cache line 变为 I,然后本地cacheline更新为M,数据写入
- cache miss
- 发BusRdX(读并独占写权限),其他 cache 嗅探后,若持有该行(M/E/S),都变为 I,内存或其他核返回数据,本 cache 状态设为M,数据写入
(3)驱除
当 cache 满了,需要替换行:
- 若该行是 M:发BusWB写回内存
- 若是 E/S:直接丢弃(因为干净)
- 若是 I:直接覆盖
CPU-DMA一致性
| 场景 | 问题 | 解决方法 |
|---|---|---|
| CPU 写 → DMA 读 | DMA 读到旧数据 | CPU 需写回缓存 (flush) |
| DMA 写 → CPU 读 | CPU 读到旧数据 | CPU 需无效化缓存 (invalidate) |
- DMA从外设–>内存:当DMA将数据写入内存后,CPU需要无效化(Invalidate)相关缓存行,确保后续读取时从主存加载最新数据
- 现代CPU缓存控制器会自动检测并无效化相关Cacheline
- 如果不支持硬件自动无效化缓存,需要手动通过一些汇编代码无效化相关Cacheline
- DMA从内存–>外设:当CPU写入数据后,可能发生Cache更新了但内存还未更新的情况,此时用DMA把内存中的数据写到外设,可能写的是旧数据,因此需要刷回(Flush)Cacheline到主存
在驱动开发时,Linux内核在DMA框架里已经提供了一整套机制来维护缓存一致性
| 操作 | 作用 | 常用函数 |
|---|---|---|
| 分配一致性内存 | 内核保证 CPU/DMA 一致 | dma_alloc_coherent() |
| 映射/同步 DMA buffer | 手动管理缓存 | dma_map_single() / dma_sync_single_for_cpu() / dma_sync_single_for_device() |
1.一致性内存:使用如下API分配,此内存位于内核空间的DMA映射区。内核通过禁用cache等机制维护缓存一致性,不需要手动 flush / invalidate
1 | void *dma_buf = dma_alloc_coherent(dev, size, &dma_handle, GFP_KERNEL); |
- 这个API的重点是缓存一致性,不一定保证分配的内存的物理地址是连续的(在有IOMMU的平台下)
- 底层立即调用
alloc_pages不会Lazy Allocation
不同架构的 CPU 和 DMA 控制器可能有==不同的==缓存一致性处理方式
X86架构:通常通过禁用Cache来保证一致性的
- CPU cache不会缓存该区域的内存,所以每次都直接从DDR读取,DMA控制器也直接从DDR读取该数据
- 缺点:没法用Cache,每次访问都是直接读DDR,效率比较低
ARM架构:
- 内核自动调用flush/invalidate Cache以及内存屏障相关的API,来保证缓存一致性
2.非一致性内存:通过dma_map_single手动映射成DMA buffer的内存属于非一致性内存,内核不会自动保证缓存同步,需要在数据方向改变时手动刷新或失效缓存
1 | // CPU→DMA前, flush cache |
- 这2个API底层都是调用了和cache相关的汇编指令
面试问题
1.二维数组是逐行读取快还是逐列读取快?为什么
- 哪种读法快取决于该语言中2维数组在内存中怎么存的。以C为例,二维数组在内存中是以行优先的方式存放的,同一行相邻元素在内存中是连续的,由于CPU每次从内存中读数据都是以Cacheline为单位,即一次会读多个字节的内容到Cache中,所以当我们访问
a[i][j]时,该行的后面多个元素a[i][j+n]都会被加载到缓存中,后边访问就比较快了。所以针对C/C++,逐行读取快
2.如何提高cache命中率
3.多核的Cache问题怎么处理?
- 硬件层面:使用缓存一致性协议(如MESI)
- 软件层面:内存屏障、原子操作
4.如何解决核内缓存一致性:
- 最直观的方式就是flush/invalidate缓存
- Linux为我们提供了个API(
dma_alloc_coherent),通过在内核空间的直接映射区分配连续内存,并且使用这块内存时关闭cache,从而避免缓存一致性问题
5.什么是Cache一致性问题
- 在多核CPU系统中,由于每个核心都有自己的缓存,同一数据可能在多个缓存中存在副本。当某个核心修改了自己的缓存数据时,其他核心的缓存副本可能仍然是旧值,导致数据不一致
- 在使用了DMA时,DMA直接修改内存中的数据,而没有更新缓存,CPU从缓存中读取数据,这也会导致数据不一致
6.什么是全相连,什么是组相连
7.PIPT、VIPT、VIVT什么意思
地址转换的实现
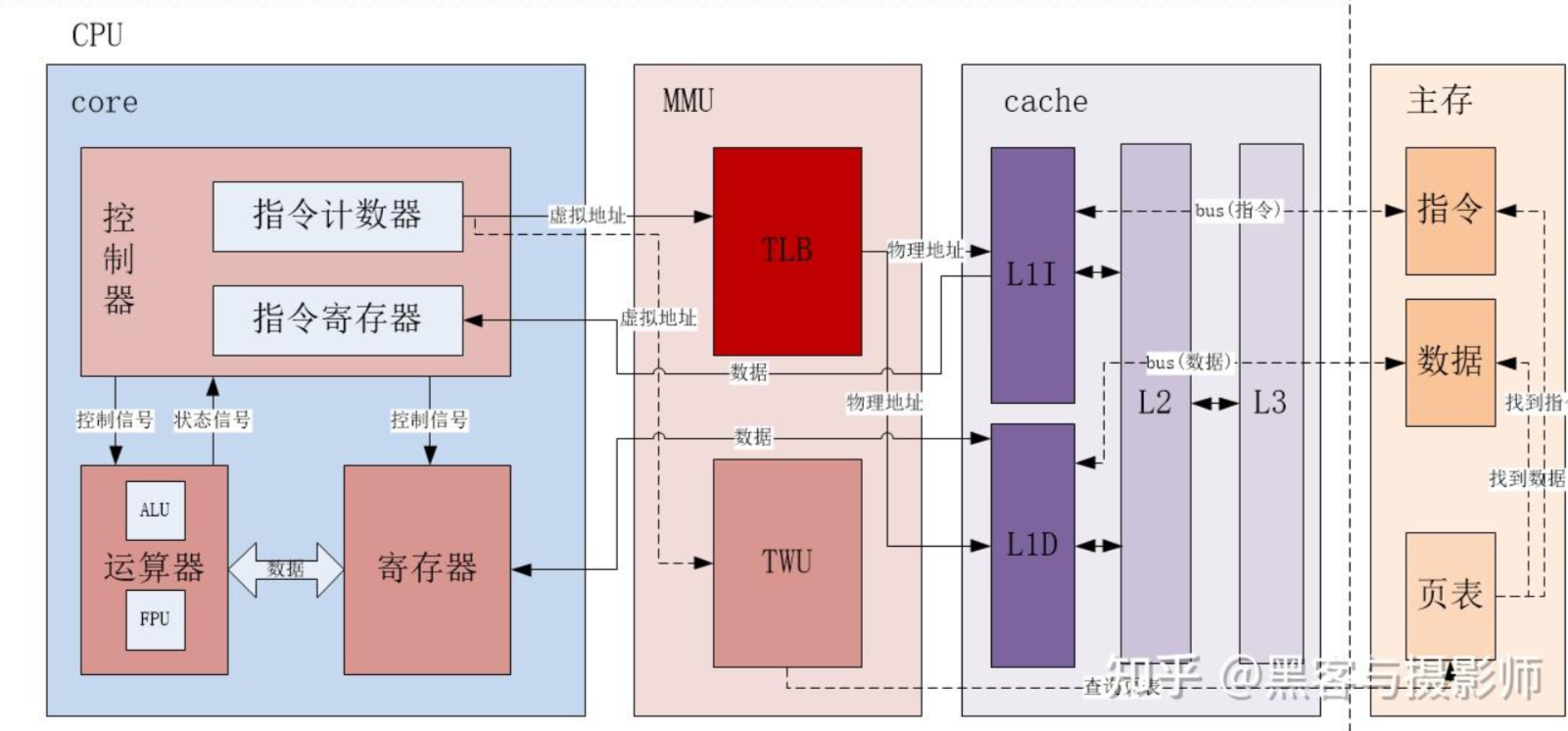
MMU
MMU(Memory Management Unit,内存管理单元)是CPU中用于管理虚拟内存和物理内存之间映射的硬件组件。它的核心功能是将程序访问的虚拟地址转换为实际的物理地址,同时进行内存保护、分页(或分段)等操作。
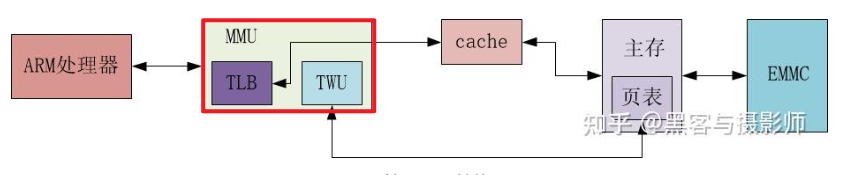
MMU的物理结构
MMU内部主要包含2个组件:
- TLB:一个高速缓存,用于缓存页表转换的结果,从而缩短页表查询的时间
- TWU:一个页表遍历模块,页表是由操作系统维护在物理内存中,但是页表的==遍历查询是由TWU完成==的,这样减少对CPU资源的消耗
MMU的主要功能
- 虚拟地址到物理地址的转换:
- 虚拟内存:现代操作系统使用虚拟内存技术,将程序的地址空间与物理内存分离。每个程序认为自己有独立的内存空间,这种空间称为虚拟地址空间
- 地址转换:当程序访问某个虚拟地址时,MMU会将该虚拟地址转换为相应的物理地址。这个过程通常通过查阅页表(Page Table)来完成,页表存储了虚拟地址与物理地址的映射关系
- 内存保护: MMU可以为不同的进程提供内存隔离,防止一个进程非法访问另一个进程的内存空间。例如,可以设置特定区域的内存为只读或禁止访问,从而增强系统的稳定性和安全性
- 分页管理:
- 分页(Paging)是将虚拟地址空间划分为固定大小的块,称为页(Page),而物理内存则被划分为同样大小的块,称为页框(Page Frame)
- MMU会使用一个页表(Page Table)来管理虚拟页和物理页之间的映射关系。每当程序访问一个虚拟地址时,MMU通过查阅页表,将虚拟地址转换为物理地址
- 当虚拟地址需要访问的页不在物理内存中/物理页被置换/权限不对时,会发生页面错误(Page Fault),操作系统会将数据从硬盘调入内存。
- 缓存管理: 为了提高虚拟地址到物理地址转换的效率,现代MMU通常配备了TLB(Translation Lookaside Buffer,翻译后备缓冲区),它是MMU内的一个高速缓存,用于存储最近使用的虚拟地址到物理地址的映射。通过查阅TLB,MMU能够更快地完成地址转换
- 分段管理(可选): 除了分页外,MMU还可以支持分段(Segmentation)机制。分段将内存划分为==大小不等==的块(段),每个段有自己的基地址和长度。程序访问某一段时,MMU根据段号和偏移量进行转换。分段可以用于更灵活的内存管理,特别是在需要支持不同类型内存区(如代码段、数据段、堆栈段等)的情况下。
MMU的工作原理
MMU是一个硬件,它对于内存的映射都是自动的,只要通过设置对应的控制寄存器就能开启MMU,在设置了其页表地址的寄存器后,再访问内存地址时,他就会自动的根据页表来把虚拟地址翻译成物理地址。且在进程切换时,也要修改对应的寄存器来切换页表
页表是就是个保存了va–>pa映射关系的一个数组,它由OS内核维护,每个PCB都有一个独立的页表
MMU的工作流程
- 程序发出对某个虚拟地址的访问请求
- MMU接收到虚拟地址,并查阅TLB来检查该虚拟地址是否有对应的物理地址映射
- 如果TLB命中,MMU直接使用该映射地址进行访问
- 如果TLB未命中,MMU查阅页表来找到虚拟地址对应的物理地址,并将该映射加载到TLB中,以备后续使用
- 当 CPU 访问一个虚拟地址时,若其对应的页表项(PTE)中不存在有效的物理地址映射(或权限不足),则会触发 Page Fault,操作系统将从硬盘加载相应的页面到内存
MMU的地址转换机制
MMU的地址转换过程通常是通过多级页表和虚拟地址的分段来实现的
虚拟地址通常分为以下几部分:
- 页目录索引(Page Directory Index)
- 页表索引(Page Table Index)
- 页内偏移(Page Offset)
TLB
TLB(Translation Lookaside Buffer,翻译后备缓冲区)是一种高速缓存,用于加速虚拟地址到物理地址的转换。注意:==TLB是MMU内部的一个组件==
TLB的作用
缓存最近使用的虚拟地址到物理地址的映射。通过缓存这些映射,TLB可以减少每次访问内存时MMU查找页表的时间,从而加速内存访问
TLB的工作原理
当CPU发出对虚拟地址的访问请求时,TLB会首先检查这个虚拟地址是否已经在缓存中
- TLB命中:如果TLB中已有该虚拟地址的映射,MMU可以直接使用该物理地址进行内存访问,无需查找页表
- TLB未命中:如果TLB中没有该映射,MMU会查找页表获取虚拟地址到物理地址的映射,并将该映射加载到TLB中,以便后续使用
TLB的结构
TLB中的每一条条目包含以下信息:
- 虚拟页号(VPN):虚拟地址中的一部分,用于在页表中查找对应的物理地址
- 物理页号(PPN):物理地址中的一部分,表示内存中的位置
- 有效位(Valid bit):标记该条目是否有效,无效条目可能会被替换
- 权限位:如只读、可执行、用户/内核模式等
- 标记位:标记该映射是否已被修改,或者用于其他一些标志
IOMMU
IOMMU(Input–Output Memory Management Unit,输入输出内存管理单元)是一个专门用于外设(DMA 设备)的 地址转换与保护单元。它在现代操作系统和硬件平台中扮演着类似于 CPU MMU 的角色,但作用对象是外设的DMA访问
作用
| 功能 | 说明 |
|---|---|
| 地址转换(DMA remapping) | 将外设发出的 DMA 虚拟地址(IOVA, I/O Virtual Address)转换为物理内存地址。设备可以使用 IOVA,就像 CPU 使用虚拟地址一样 |
| 隔离保护 | 防止外设访问不属于自己的内存区域,类似于 CPU 的内存保护,增强系统安全 |
| 支持虚拟化 | 在虚拟机环境中,IOMMU 可以让多个虚拟机安全地共享物理设备,同时每个虚拟机看到的 DMA 地址是虚拟化后的地址 |
| 扩展 DMA 能力 | 支持 64 位 DMA 地址、打破物理连续性限制;设备不再必须访问物理连续内存 |
打破物理连续性限制
没有 IOMMU 时,设备进行 DMA 访问时必须访问物理连续内存,这在大内存、碎片化严重的系统中很难保证
有了 IOMMU,设备可以访问 不连续物理页,IOMMU 会把连续的 IOVA 映射到实际的物理页
增加安全性
防止 DMA 攻击(恶意设备或驱动访问任意内存)
通过 IOMMU,可以只允许设备访问指定的内存区域
支持虚拟化
虚拟机中的设备可以访问 DMA 虚拟地址
IOMMU 将这些地址映射到宿主机的物理内存,实现 DMA 隔离
工作原理
- 设备发出 DMA 请求,提供 IOVA(类似虚拟地址)
- IOMMU 查 页表,将 IOVA 转换为实际物理地址
- DMA 控制器通过物理总线访问物理内存
- CPU 也可以通过内核提供的接口管理 IOMMU 表
面试问题
1.说下CPU访问内存过程
- 首先看TLB缓存是否命中。命中的话直接使用TLB中的映射地址进行访问
- 若TLB未命中,CPU会发出请求,请求MMU进行地址转换,MMU会先检查页表是否有该虚拟地址的映射,如果有,MMU会将该映射加载到TLB中,以备后续使用
- 如果页表中没有该映射,MMU会发出Page Fault,操作系统会将数据从硬盘调入内存,然后再将该映射加载到TLB中,以备后续使用
2.有没有操作过MMU
- XV6开发中操纵RISC-V的
satp寄存器,修改页表基址、几级页表 - 切换页表是使用
sfence.vma指令,刷新TLB缓存
3.知道MMU吗?
4.如何快速的去操作内存地址?
- 减少内存访问次数:用批量访问代替逐字节访问
- 提高缓存命中率
- 使用内存池,避免频繁分配内存
5.MMU实现内存地址映射的原理
- 以RISC-V的sv39分页机制为例,对于RV64来说,虽然一个地址有64位,但只有低39位有效,这39为又可看成4部分,高27位分别是L0、L1、L2级page directory中PTE的索引,低12位为页内偏移,在进行地址转换时,首先将当前进程的页目录基址装载到
satp寄存器,然后进行TWU,经过多级页表,找到最后的PTE,里面存了相应的物理页号,再加上页内偏移,得到物理地址,完成地址转换
6.什么是IOMMU
- IOMMU是集成在 SoC 系统互连中的硬件单元,它位于外设(如 GPU、网卡)和主内存之间。它的核心功能是为设备发起的 DMA 操作提供地址转换(将设备虚拟地址 IOVA 映射为物理地址 PA),从而实现内存保护、隔离(防止恶意 DMA 访问)和 I/O 虚拟化(让虚拟机安全使用物理设备)
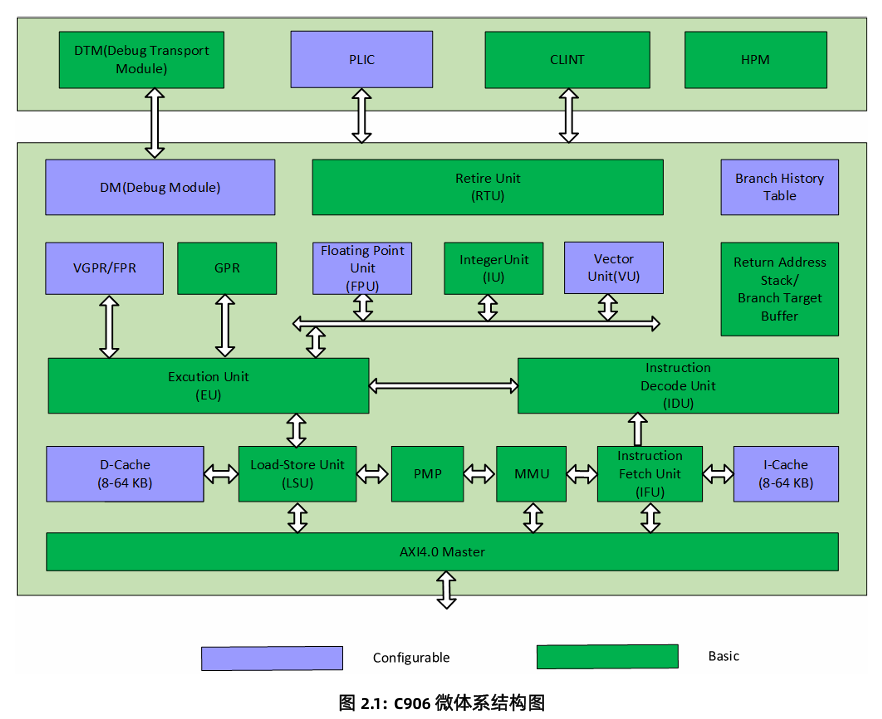
C906微架构