
04 SoC与系统架构
SoC与系统架构
SoC/MCU/MPU/CPU的区别
SoC是将一个完整的系统整合到单一芯片上的集成电路,包括 CPU、GPU、存储控制器、外设接口、专用加速器(GPU/NPU/VOP)等
- SoC 不一定有片上 RAM(有些会集成 LPDDR),但一定有外部内存接口
MCU是一种集成了CPU、内存(如闪存、RAM)、以及多种外设(如ADC、DAC、串行通信接口、定时器等)于一体的芯片,可以看成简易版的SoC。与SoC的核心区别:
MCU通常不跑复杂OS(最多RTOS),但是SoC一般跑Linux/Android之类的
MCU的片上RAM/ROM都比较小,功耗比较低
MPU:不带片上 Flash/RAM,需要外部存储器的处理器芯片,一般只包括CPU核心+外设控制器,必须配合外部的RAM+ROM才能运行,适合跑Linux/Android之类的复杂操作系统。(注意:ARM里还有个叫内存保护单元的MPU,和这里不是一个东西)
CPU就只是CPU内核,包括运算器、控制器、寄存器、Cache等
x86架构的电脑通常会有个主板,将CPU芯片和各个外设芯片通过总线连接
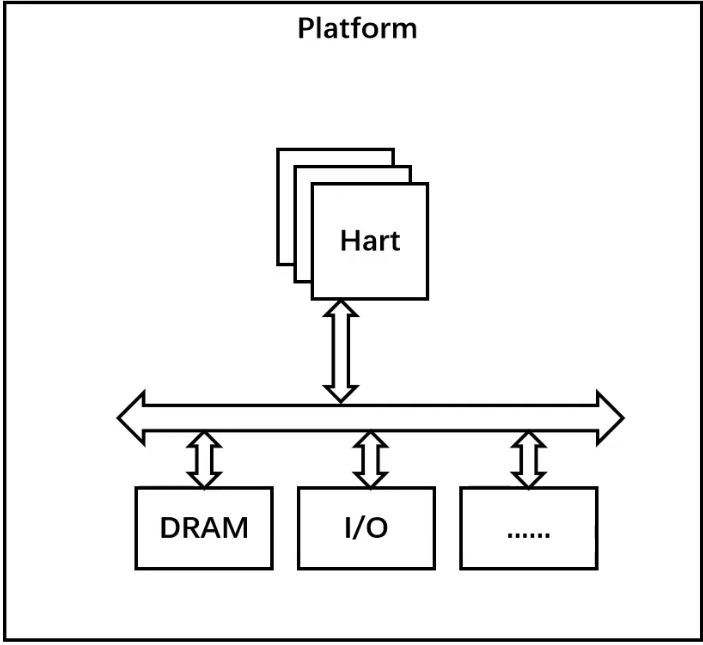
嵌入式系统的SOC/MCU是把CPU和各个外设都集成到了一个芯片里,这是他们很大的一个区别


MCU和SoC的区别主要体现在:
- 处理能力
- 应用场景
- 功耗
- 集成度:
- MCU集成的资源有限,主要用于控制任务,而非复杂计算
- 而SOC通常是一个完整的系统集成在一块芯片上,集成度更高。比如有MCU上没有的屏幕驱动部分、GPU等
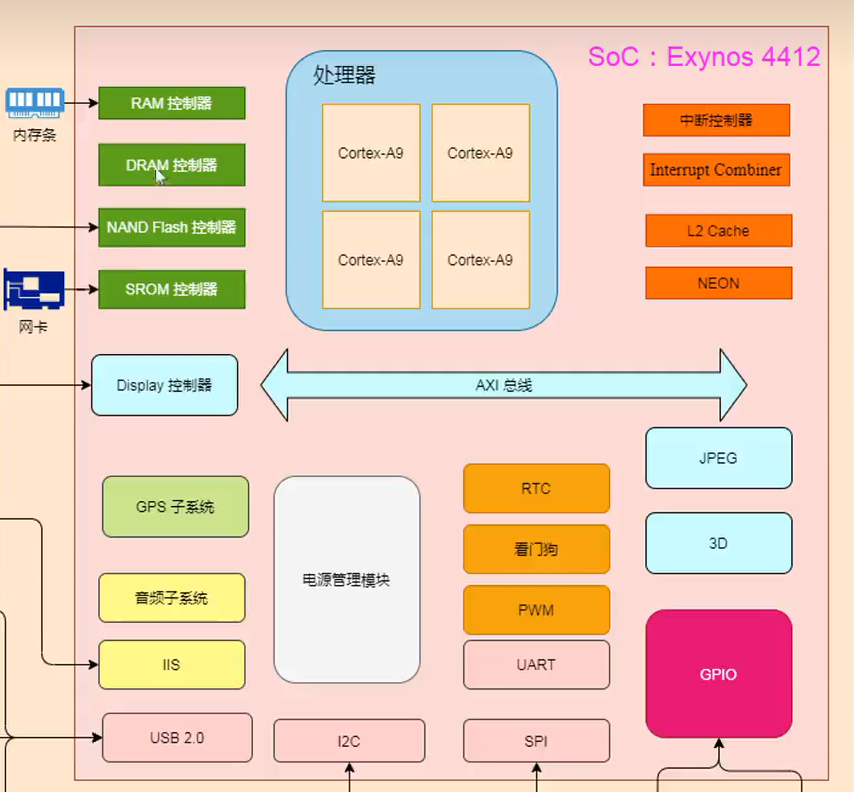
由于SOC中集成了很多模块,那么软硬件工程师的工作量也会减少,如果用裸CPU,那么什么RAM、FLASH的电路都得自己画,但是如果SOC自带了,那么就不需要了啊
总线的本质
总线不仅仅就是几根线,它包括一套协议以及对应的控制器
总线是指计算机组件间规范化的交换数据的方式,即以一种通用的方式为各组件提供数据传送和控制逻辑
对于总线而言,有以下比较重要的性能指标或者是概念需要掌握:
- 总线带宽:指的是单位时间内总线上传送的数据量;其大小为总线位宽*工作频率(单位为bit,但通常用Byte表示,此时需要除以8)
- 总线位宽:指的是总线有多少比特,即通常所说的32位,64位总线
- 总线时钟工作频率:以MHz或者GHz为单位
- 总线延迟:一笔传输从发起到结束的时间。在突发传输中,通常指的是第一笔的发起和结束时间之间的延迟(什么事是突发传输后面再讲)
分类
总线可以分为片上总线和片外总线:
- 片上总线:同一个芯片上不同模块之间的一种规范化交换数据的方式。比如AMBA引入的AHB、APB、AXI等…基于片上总线,我们可以非常迅速的搭建SoC
- 片外总线:两颗芯片或者两个设备之间的数据交换传输方式,比如UART、SPI、IIC、CAN、PCIe、USB…
总线的组成
总线通常由多个信号线组成,每一条信号线承担不同的功能,一种总线由以下部分组成:
- 数据总线:用于传输数据,数据总线的宽度(即信号线的数量)决定了每次传输的数据量,通常为8位、16位、32位或64位
- 地址总线:用于传输内存地址或外设的地址。地址总线的宽度决定了系统能够访问的内存空间的大小。例如,32位地址总线可以寻址2^32个内存地址(即4GB内存)
- 控制总线:用于传输控制信号,协调各个硬件部件的工作。例如,控制信号可以指示内存是否需要读取或写入数据,或者表示数据的方向(从CPU到内存还是从内存到CPU)
总线的工作原理
总线的工作原理依赖于计算机系统中不同组件之间的协调。具体来说,数据传输过程通常包括以下几个步骤:
- 发起传输请求:当CPU需要从内存读取数据或向内存写入数据时,它通过控制总线发起传输请求
- 地址传输:CPU将目标地址传送到地址总线上,标明要访问的内存位置或外设地址
- 数据传输:数据通过数据总线传输到目标组件,数据总线将存储在寄存器中的数据传输到内存或外设,反之亦然
- 控制信号:控制总线发送信号来确保数据传输的正确性,如控制读/写操作、数据传输的方向等
片上互联总线
对于SoC内部各个模块之间连接,我们通常不会用像I2C、SPI、USB之类的协议,而是用专用的片上互联总线。对于嵌入式平台来说,最常用的协议是AMBA
AMBA
AMBA(Advanced Microcontroller Bus Architecture,高级微控制器总线架构)定义了SoC内部的RISC CPU和其他硬件模块如何连接,基于AMBA总线,可以快速的将各个模块连接起来,构建一个SoC
AMBA是个协议簇,它包含了许多协议,比如:
- AHB(Advanced High-performance Bus) 高级高性能总线
- APB (Advanced Peripheral Bus) 高级外设总线
- AXI (Advanced eXtensible Interface) 高级可拓展接口
- ASB (Advanced System Bus) 高级系统总线——用的很少
- ……
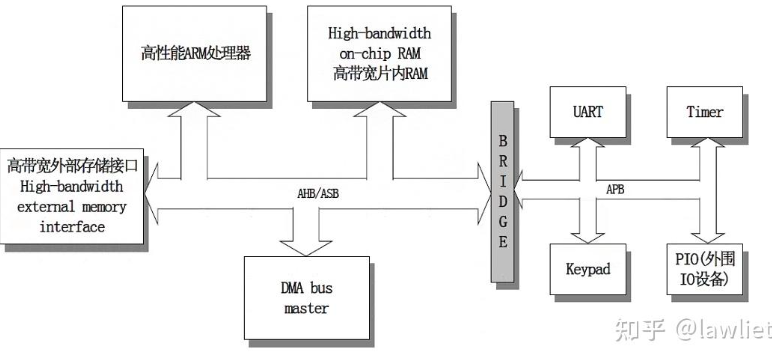
在SoC设计时,各个IP核如果要通过AMBA里的协议和其他模块连接,内部得包含相关协议的wrapper(协议适配层)在IP的内部逻辑和系统总线之间做协议映射
在一个典型的基于 ARM Cortex-A 的 SoC 中,总线结构通常如下所示:
1 | [ CPU ] [ GPU ] [ DMA ] (高性能主设备) |
AHB
AHB总线用于连接高速模块,包括ARM的处理器,片内RAM、DMA Master等。它采用共享总线架构,支持多个主设备和从设备,但是同一时刻总线上只有一个主设备驱动信号线。此外他还包括一个仲裁器,用于选择主设备,一个译码器来选择从设备,顾硬件架构分为5部分:
- Master
- Slave
- 仲裁器
- 译码器
- 多路选择器(Multiplexer)
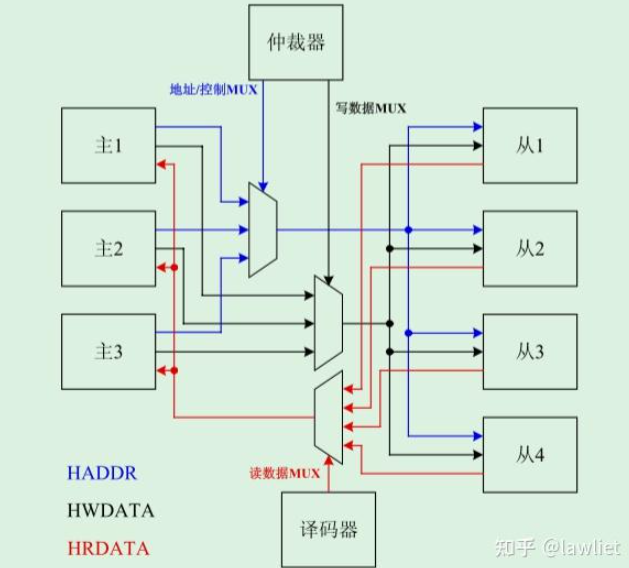
MUX(多路选择器)是数电里的基本电路,有多路输入信号和选择信号,通过选择信号(仲裁器/译码器)来决定最终的输出
在一些场景下,只有单个Master,此时用AHB可能过于复杂,于是ARM又提出了AHB-Lite协议,它支持单主多从,并且没有仲裁器了
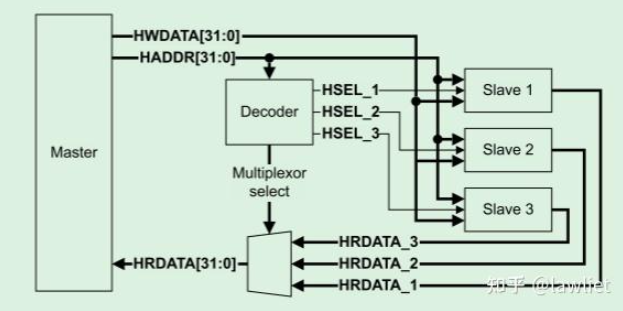
APB
APB总线用于连接低速、低功率的一些外设比如GPIO、SPI、UART、IIC等。它是个单主多从的总线。APB通常位于 AHB 或 AXI 总线的下游,通过桥接器(Bridge)连接
APB总线包含以下3个模块:
- APB Bridge:从AHB/AXI接收指令和数据,转成 APB 时序和信号,是 APB 的唯一Master
- 译码器:根据地址选择要访问的从设备,产生
PSELx信号 - APB Slave:被访问的外设模块(UART、GPIO、Timer 等),响应
PSEL、PENABLE信号,返回数据
AXI
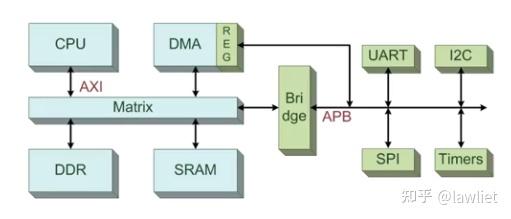
AXI 是 AMBA 架构下的高性能总线协议,它通过“读写分离 + 多通道并行 + 灵活握手”机制,为SoC模块之间提供了统一且高效的数据通信方式。主要用于连接CPU、高速外设(DMA、GPU、NPU)、DDR、SRAM等
实际上现在的SoC中AHB已经很少使用了。除非是很低端的MCU,考虑到节省功耗和面积等因素,才会去使用AHB总线。目前更多的SoC采用AXI总线来连接一些高速模块
总线矩阵
在SoC中如果直接使用AHB+MUX连接多个主设备和从设备,实际上效率会非常低的,因为同一时刻只能有一个主设备驱动总线。因此人们提出总线矩阵,它是一种多主多从的片上互连(On-Chip Interconnect)架构,它允许多个主设备(例如 CPU、DMA 控制器)同时访问多个从设备(例如 SRAM、外设寄存器、DDR 控制器),而不需要像传统单总线那样串行访问,但是同一个从设备同时只能被一个主设备访问,所以仍有仲裁器
一个总线矩阵内部包含以下模块:
- 主接口(Master Interface):与主设备(如 CPU、DMA)连接
- 从接口(Slave Interface):与从设备(如存储器、外设)连接
- 地址解码器(Address Decoder):判断访问目标属于哪个从设备
- 仲裁器(Arbiter):每个从设备都有一个,当多个主设备同时请求时决定谁先访问
- 通道(Channel):连接主从之间的独立数据路径,可并行工作
常见实现:
- AMBA AHB Matrix:出现在 Cortex-M3/M4/M7 等 MCU 中(如 STM32F4)
- AMBA AXI Interconnect:出现在 Cortex-A 系列 SoC(如 i.MX6ULL、RK3568、全志A系列)
面试问题
1.寄存器地址到底是什么?为什么每个外设在物理地址空间中会有自己的一段地址
- CPU 并不直接“认识外设”或“芯片模块”,它只知道“能访问的一切资源都通过地址访问”。所以SoC中一切资源(RAM、ROM、外设)全部都被映射到一个统一的物理地址空间中
2.CPU访问内存地址的时候,怎么知道哪个地址对应RAM,哪个地址对应GPIO的呢
- 每个SoC在设计阶段,都会由硬件工程师定义一张内存映射表,这张表规定了每个模块在物理地址空间中所占的区域,例如
- 0x00000000 ~ 0x0FFFFFFF → 内存
- 0x10000000 ~ 0x1FFFFFFF → 外设
- 0x20000000 ~ 0x2FFFFFFF → 调试模块
- …
- 这张表由总线矩阵实现,AHB/AXI总线译码逻辑会根据地址选择哪个从设备
3.为什么访问外设寄存器时要ioremap
- 因为外设寄存器在物理地址空间中,必须映射到内核虚拟地址空间中才能被CPU访问
4.SoC 中 CPU 是如何访问外设寄存器的
- 通过 AXI/AHB 总线,经过 AXI-APB Bridge 访问外设


