DMA子系统
概述
DMA(Direct Memory Access)是用于高效数据传输的一种技术,能够实现外设和内存之间直接交换数据,而无需CPU干预,它通常以独立的控制器存在。DMA不仅减轻了CPU负担,提高了数据传输效率,还能在数据传输过程中保持CPU的计算能力
传输模式
DMA有几种常见的传输模式,具体方式取决于传输的源和目标设备以及数据的传输方向:
- 内存到内存
- 通常用于大数据块的移动,如从一个缓冲区复制数据到另一个缓冲区
- 外设到内存
- 比如一个传感器的测量结果可以直接写入内存供后续处理
- 内存到外设
- 比如将数据从内存直接写入到输出设备(如DAC、显示器)
- 外设到外设
硬件组成
DMA控制器跟其他外设的控制器一样,内部有很多寄存器。除此之外,还引入“通道”概念。DMA通道指的是可以完成一次数据传输的硬件资源集合,每个通道都有一组独立的寄存器:
- 源地址寄存器
- 目标地址寄存器
- 传输计数器
- 控制与状态寄存器:方向、通道使能、中断使能、宽度…
DMA通道 = 一套私有寄存器 + 地址生成器 + 总线请求逻辑
DMA控制器 = 多个通道 + 仲裁器 + 总线接口 + 外设握手逻辑
典型工作流程
DMA 传输的核心是 DMA 控制器(DMA Controller),它是一个独立于 CPU 的硬件组件,负责协调外设与内存的数据传输。典型工作流程如下:
- 请求阶段:外设(如网卡)需传输数据时,向 DMA 控制器发送 DMA 请求(DREQ)
- 授权阶段:DMA 控制器向 CPU 发送总线请求(HRQ),CPU 响应并释放总线控制权(HLDA)
- 传输阶段:DMA 控制器接管总线,直接在内存与外设间传输数据(通过指定内存地址、外设地址、传输长度和方向)
- 完成阶段:传输结束后,DMA 控制器向 CPU 发送中断,通知传输完成,CPU 恢复总线控制权
硬件方案
使用DMA的场景必须得有DMA控制器,根据DMA控制器的位置又有2种方案:
通用DMA控制器
- SoC有独立DMA控制器,可给多个外设复用
- 此时DMA控制器可以看成一种被共享的资源,如何使用它需要通过设备树来指定
- 这种情况下需要使用DMA Engine框架种定义的标准API来对DMA控制器进行操作
- 之前用的STM32就是这种方案
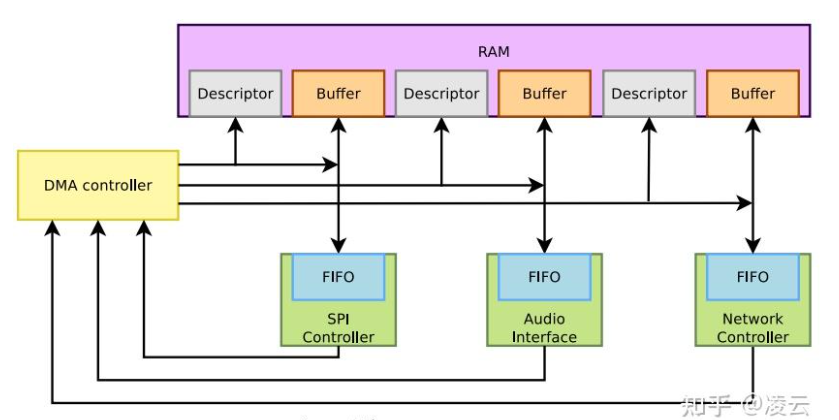
外设自带的DMA控制器
- 一些高速总线的设备可能自带了DMA控制器,比如之前用的qemu的edu pcie设备
- 此时没法用DMA Engine框架来进行DMA操作,而是直接通过PIO来写外设中的DMA控制寄存器,从而触发DMA的操作
1
2
3
4
5
|
iowrite32(host_addr, edu->mmio + EDU_DMA_SRC);
iowrite32(EDU_DMA_BUFFER, edu->mmio + EDU_DMA_DST);
iowrite32(len, edu->mmio + EDU_DMA_CNT);
iowrite32(EDU_DMA_START, edu->mmio + EDU_DMA_CMD);
|
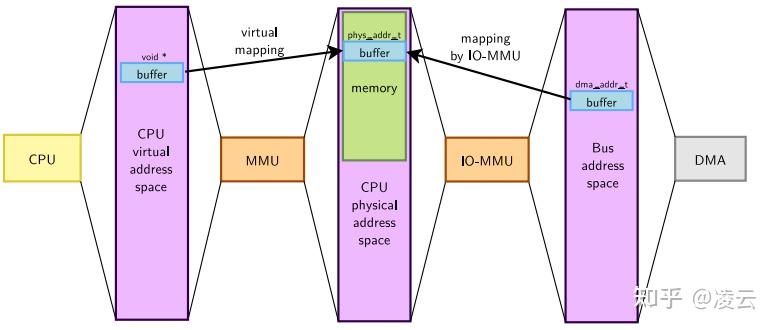
地址空间
CPU和外设(如DMA控制器)不在同一个地址空间,比如RAM在CPU的视角可能是地址是A,而在DMA控制器的视角就是地址B了,所以要对地址加以区分
CPU的视角有2个地址
- PA(
phys_addr_t):物理地址,一般不能直接使用,与VA的映射关系保存在page table中
- VA(
void *):就是最常见的虚拟地址空间的地址
外设的视角有1个地址
- IOVA(
dma_addr_t):经IOMMU映射过的虚拟地址,也叫总线地址
使用DMA时,因为是DMA帮我们搬运数据,所以得站在它的视角来看。得使用IOVA而不是CPU看到的VA
内核框架
Linux的DMA子系统跟其他子系统类似,都采用分层的架构,自下向上分为以下几层:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| 用户空间 (Userspace)
↓ 使用 dma-buf fd
-----------------------------------------
DMA-BUF 框架层 (drivers/dma-buf/)
├── dma-buf.c ← 共享缓冲区对象管理
├── dma-fence.c ← 同步机制
└── dma-heap.c ← DMA Heap核心
├── system-heap (系统内存)
├── cma-heap (连续内存)
└── 厂商自定义堆
↓ 调用底层分配
-----------------------------------------
DMA Engine 框架层 (drivers/dma/)
└── dmaengine.c ← 传输控制 (与 DMA Heap 无关)
-----------------------------------------
DMA Mapping 层 (kernel/dma/)
└── mapping.c ← 地址转换/一致性
-----------------------------------------
DMA控制器驱动
|
主机驱动层
这一层是DMA控制器的驱动,由各芯片原厂维护,主要职责包括:
- 实现特定硬件DMA控制器的操作集
- 管理虚拟通道和物理通道的映射
- 处理中断、错误和完成状态
核心层
DMA子系统的核心层的作用也是提供一些通用的API,它本身又可分为3个模块
DMA Mapping
该模块主要处理CPU与DMA地址映射,以及缓存一致性问题
根据使用场景,Linux将DMA又分成了3种使用类型:
一致性DMA(Coherent DMA)
定义:CPU 与 DMA 控制器对内存的访问始终保持一致(无缓存不一致问题)
特点:
- 内存区域在分配时即保证物理连续,且对 CPU 和 DMA 可见
- 通常用于设备需要持续访问的缓冲区(如设备固件、环形缓冲区)
- 实现方式:
- 禁用缓存(低速)
- 依赖硬件缓存一致性(如 ARM 的CCI 或 x86 的 MESI 协议)
1
2
3
4
5
6
7
8
|
[include/linux/dma-mapping.h]
void *dma_alloc_coherent(struct device *dev, size_t size,
dma_addr_t *dma_handle, gfp_t gfp);
void dma_free_coherent(struct device *dev, size_t size,
void *cpu_addr, dma_addr_t dma_handle);
|
流式DMA(Streaming DMA)
定义:临时用于单次数据传输的 DMA,传输前后需显式同步CPU 缓存与内存
特点:
- 内存区域可临时映射给 DMA 使用,传输完成后解除映射
- 需指定传输方向(如
DMA_TO_DEVICE、DMA_FROM_DEVICE),内核自动处理缓存刷新/失效
- 适用于 短期、单次的数据传输(如磁盘读写单个扇区)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
[include/linux/dma-mapping.h]
dma_addr_t dma_map_single(struct device *dev, void *cpu_addr,
size_t size, enum dma_data_direction dir);
void dma_unmap_single(struct device *dev, dma_addr_t dma_addr,
size_t size, enum dma_data_direction dir);
void dma_sync_single_for_cpu(struct device *dev, dma_addr_t addr,
size_t size, enum dma_data_direction dir);
void dma_sync_single_for_device(struct device *dev, dma_addr_t addr,
size_t size, enum dma_data_direction dir);
|
传输方向:
DMA_TO_DEVICE:数据从内存传输到设备(CPU 先写内存,DMA 读内存)DMA_FROM_DEVICE:数据从设备传输到内存(DMA 写内存,CPU 后读内存)DMA_BIDIRECTIONAL:双向传输(如 USB 批量传输)
注意,这里是我们自己先分配一段内存,然后让他具备DMA的功能,分配时不能使用会得到物理上不连续的内存的API比如vmalloc
散射-聚集 DMA(Scatter-Gather DMA)
定义:支持 DMA 控制器直接访问非连续内存区域的传输方式
特点:
- 通过
sg_table 结构描述多个分散的内存段(物理页),DMA 控制器按顺序传输
- 避免内存拷贝(无需将分散数据合并为连续缓冲区),提升效率
- 适用于大数据量、非连续内存场景(如网络协议栈中的skb 缓冲区、文件系统的分散读/写)
1
2
3
4
5
6
7
8
9
|
struct sg_table *sg_alloc_table(int nents, gfp_t gfp_mask);
void sg_free_table(struct sg_table *sgt);
int dma_map_sg(struct device *dev, struct scatterlist *sg,
int nents, enum dma_data_direction dir);
void dma_unmap_sg(struct device *dev, struct scatterlist *sg,
int nents, enum dma_data_direction dir);
|
sg_table:散射-聚集表,包含多个 scatterlist 条目(每个条目描述一个物理页)nents:条目数量
DMA Engine
dmaengine 是 Linux 内核中用于统一管理通用 DMA 控制器的框架。当 SoC 中有独立的、可被多个外设共享的 DMA 控制器时,外设驱动应通过 DMA Engine API 来申请通道、提交传输、等待完成
核心结构体:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
struct dma_chan {
struct device *device;
void *private;
};
struct dma_device {
struct list_head channels;
struct dma_async_tx_descriptor *(*device_prep_dma_memcpy)(...);
struct dma_async_tx_descriptor *(*device_prep_slave_sg)(...);
struct dma_async_tx_descriptor *(*device_prep_dma_cyclic)(...);
};
struct dma_async_tx_descriptor {
dma_cookie_t (*tx_submit)(struct dma_async_tx_descriptor *tx);
struct dma_async_tx_descriptor *(*callback)(...);
void *callback_param;
};
|
核心API:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| #include <linux/dmaengine.h>
struct dma_chan *dma_request_chan(struct device *dev, const char *name);
void dma_release_channel(struct dma_chan *chan);
int dmaengine_slave_config(struct dma_chan *chan, struct dma_slave_config *cfg);
struct dma_slave_config {
enum dma_transfer_direction direction;
dma_addr_t src_addr;
dma_addr_t dst_addr;
u32 src_addr_width;
u32 dst_addr_width;
u32 src_maxburst;
u32 dst_maxburst;
};
struct dma_async_tx_descriptor *dmaengine_prep_dma_memcpy(
struct dma_chan *chan, dma_addr_t dst, dma_addr_t src, size_t len, unsigned long flags);
struct dma_async_tx_descriptor *dmaengine_prep_slave_sg(
struct dma_chan *chan, struct scatterlist *sgl, unsigned int sg_len,
enum dma_data_direction direction, unsigned long flags);
struct dma_async_tx_descriptor *dmaengine_prep_dma_cyclic(
struct dma_chan *chan, dma_addr_t buf_addr, size_t buf_len, size_t period_len,
enum dma_transfer_direction direction, unsigned long flags);
dma_cookie_t dmaengine_submit(struct dma_async_tx_descriptor *desc);
void dma_async_issue_pending(struct dma_chan *chan);
enum dma_status dma_sync_wait(struct dma_chan *chan, dma_cookie_t cookie);
|
DMA Buf
dma-buf 是 Linux 内核中用于跨驱动、驱动与用户态之间共享内存的一种机制,核心目标是实现零拷贝的数据传输。通过文件描述符(fd)在不同进程/驱动间传递内存句柄
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
struct dma_buf {
size_t size;
struct file *file;
struct dma_buf_attachment *attachments;
const struct dma_buf_ops *ops;
void *priv;
};
struct dma_buf_attachment {
struct dma_buf *dmabuf;
struct device *dev;
struct list_head node;
struct sg_table *sgt;
enum dma_data_direction dir;
void *priv;
};
struct dma_buf_ops {
int (*attach)(struct dma_buf *dmabuf, struct dma_buf_attachment *attach);
void (*detach)(struct dma_buf *dmabuf, struct dma_buf_attachment *attach);
struct sg_table *(*map_dma_buf)(struct dma_buf_attachment *attach,
enum dma_data_direction dir);
void (*unmap_dma_buf)(struct dma_buf_attachment *attach,
struct sg_table *sg, enum dma_data_direction dir);
int (*mmap)(struct dma_buf *dmabuf, struct vm_area_struct *vma);
void (*release)(struct dma_buf *dmabuf);
};
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
int dma_buf_begin_cpu_access(struct dma_buf *dmabuf,
enum dma_data_direction direction);
int dma_buf_end_cpu_access(struct dma_buf *dmabuf,
enum dma_data_direction direction);
struct sg_table *dma_buf_map_attachment(struct dma_buf_attachment *attach,
enum dma_data_direction direction);
void dma_buf_unmap_attachment(struct dma_buf_attachment *attach,
struct sg_table *sg_table,
enum dma_data_direction direction);
|
使用示例:
1.驱动侧(导出者)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
struct sg_table *sgt;
void *cpu_addr;
dma_addr_t dma_handle;
DEFINE_DMA_BUF_EXPORT_INFO(exp_info);
exp_info.ops = &my_dmabuf_ops;
exp_info.size = buf_size;
exp_info.flags = O_RDWR;
exp_info.priv = private_data;
struct dma_buf *dmabuf = dma_buf_export(&exp_info);
int fd = dma_buf_fd(dmabuf, O_CLOEXEC);
|
2.驱动侧(消费者)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
struct dma_buf *dmabuf = dma_buf_get(fd);
if (IS_ERR(dmabuf))
return PTR_ERR(dmabuf);
struct dma_buf_attachment *attach = dma_buf_attach(dmabuf, dev);
if (IS_ERR(attach)) {
dma_buf_put(dmabuf);
return PTR_ERR(attach);
}
struct sg_table *sgt = dma_buf_map_attachment(attach, DMA_BIDIRECTIONAL);
dma_buf_unmap_attachment(attach, sgt, DMA_BIDIRECTIONAL);
dma_buf_detach(dmabuf, attach);
dma_buf_put(dmabuf);
|
3.应用层
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
int dmabuf_fd = driver_alloc_dmabuf(size);
int heap_fd = open("/dev/dma_heap/system", O_RDWR);
struct dma_heap_allocation_data alloc = {
.len = size,
.fd_flags = O_CLOEXEC,
};
int ret = ioctl(heap_fd, DMA_HEAP_IOCTL_ALLOC, &alloc);
int dmabuf_fd = alloc.fd;
ioctl(gpu_fd, GPU_SET_INPUT_BUFFER, dmabuf_fd);
void *ptr = mmap(NULL, size, PROT_READ | PROT_WRITE,
MAP_SHARED, dmabuf_fd, 0);
|
设备驱动层
使用了DMA的具体设备的驱动,通常还是需要结合字符设备/块设备/网络设备以及各种总线的框架来实现。
典型的设备驱动:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| struct dma_chan *chan;
struct dma_slave_config cfg;
struct dma_async_tx_descriptor *desc;
dma_cookie_t cookie;
chan = dma_request_chan(dev, "rx");
cfg.direction = DMA_DEV_TO_MEM;
cfg.src_addr = my_peripheral_phys_addr;
cfg.src_addr_width = DMA_SLAVE_BUSWIDTH_4_BYTES;
cfg.src_maxburst = 4;
dmaengine_slave_config(chan, &cfg);
desc = dmaengine_prep_slave_sg(chan, sgt->sgl, sgt->nents,
DMA_DEV_TO_MEM, DMA_PREP_INTERRUPT);
desc->callback = my_complete_cb;
desc->callback_param = my_ctx;
cookie = dmaengine_submit(desc);
dma_async_issue_pending(chan);
dma_sync_wait(chan, cookie);
|
QA
QA1:DMA-buf到底如何使用或者实现,到底是应用层还是驱动层呢?
- 通常是驱动和应用层结合,比如V4L2、RK的MPP、RGA、NPU的SDK中都支持以DMA-buf的
fd作为输入。用户只需要一开始在应用层申请一块dma-buf,然后把它传给各个模块的SDK,就可以实现数据通过dma-buf在各个驱动之间零拷贝了。当然,这需要在驱动里通过dma-buf框架来实现。所以dma-buf的使用、pipeline的搭建不只是应用层或者驱动层单独就能完成得了
QA2:使用DMA时需要用设备树吗?
- 分情况,如果使用了SoC公用的DMA控制器,则需要使用DMA Engine框架,此时需要用设备树;如果用的是设备自带的DMA控制器,则不需要,只需要用DMA Mapping框架就行了
QA3:为什么需要dma_buf_attachment ?
- dma-buf的引用计数与生命周期管理,当最后一个attachement被deattach时,会释放内存
- 不同设备可能有不同的 IOMMU 页表,同一个 dma-buf 在不同设备眼中看到的 IOVA 可能不同。
attachment->sgt 保存了为这个设备专属映射的sg_table
- 不同设备的 cache 一致性需求不同,attachment 可以携带特定设备的同步策略
QA3:dma-buf需要手动同步吗?
- 由CPU访问:需要调用
dma_buf_begin_cpu_access() 和 dma_buf_end_cpu_access()进行同步
- 由DMA控制器访问:使用
dma_buf_map_attachment映射后就自动处理cache一致性了,不用手动同步
参考链接



